
Poetiq and the Reasoning Layer
How recursive self-improvement turns frontier LLMs into more reliable specialists, without training a new model.

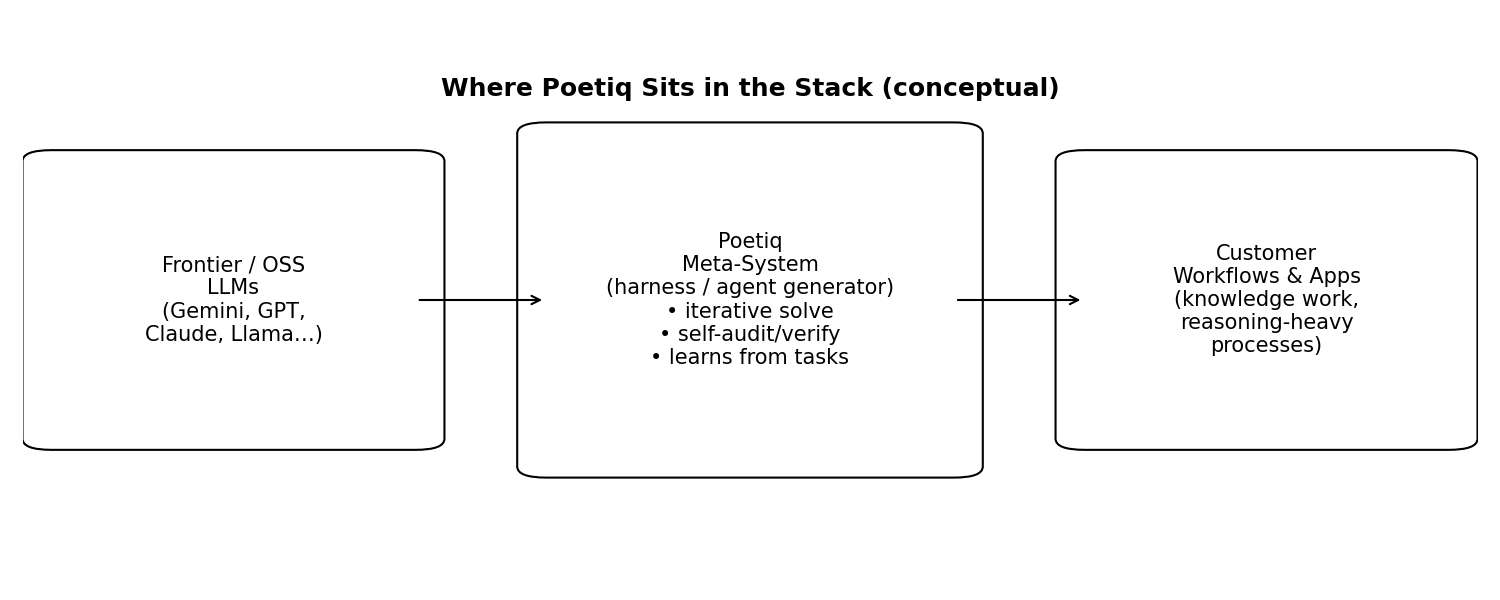
Poetiq builds a model-agnostic reasoning layer that uses recursive self-improvement to turn existing large language models into more reliable, task-specific problem solvers. It is an AI meta-system that sits on top of frontier LLMs and generates specialized agents/harnesses that outperform the underlying model on a given task.
It is not positioning itself as the next base model company. The pitch is that LLMs are amazing databases but unreliable at deep reasoning and at retrieving the right fragments of knowledge on demand. The remedy is to build a full ecosystem around the model, an orchestrator that learns how to ask better questions and synthesize the fragments into a correct, checkable answer.
The customer is hiring Poetiq to reduce the permanent-loss risk of deploying LLMs in real workflows by improving accuracy and efficiency without betting the company on a single model vendor. Poetiq is selling discipline. A repeatable method for buying more correctness per dollar of inference.
Why LLMs Fail Where Business Cares
Enterprises can pay for a powerful LLM today, but they can’t reliably make it reason through messy, domain-specific workflows without either paying a fortune (post-training) or accepting brittle, hallucination-prone behavior.
The typical buyer is an AI/product team that wants an LLM to do real work: support agents, triage queues, interpret policies, stitch together facts, or drive multi-step decisions. In production, the tail risk dominates. A model that is usually right still fails in ways that are expensive, hard to predict, and hard to debug. The outcome is a familiar enterprise pattern. Pilots everywhere, scaled deployments nowhere.
There are three broad default tactics today. First, prompt engineering and orchestration (agent frameworks, prompt templates, routing). Fast to ship, but often brittle. Small changes in inputs can flip outputs, and long-horizon tasks accumulate error. Second, retrieval-augmented generation (RAG). Helpful for fresh facts, but it can’t guarantee reasoning quality, and it introduces retrieval and citation failure modes. Third, model tuning (fine-tuning or reinforcement-learning post-training). It can improve task performance, but Poetiq argues it is slow, expensive, and data-hungry. Often requiring “thousands or millions” of examples and weeks of iteration that only the largest labs can justify.
The bottleneck is an imbalance. Model vendors spend enormous effort encoding knowledge into weights, while most application builders lack a systematic way to extract and assemble the right fragments under uncertainty.
The Trick: Recursive Self-Improvement
Poetiq wraps an LLM with an automated improvement loop. Generate an agent/harness, test it on a few hundred examples, and iteratively refine the system until it becomes both more accurate and more cost-efficient for that specific problem.
The premise is that many failures are not missing knowledge but missing access. The relevant information is present in the model’s weights, but hidden in fragments. Instead of pushing intelligence into the base model via retraining, Poetiq tries to build intelligence on top of the model. An orchestrator that discovers what questions to ask next, probes the model, and stitches the fragments into a coherent answer.
The trade is data-efficiency and speed. Rather than “thousands or millions” of examples (or massive RL post-training), customers can provide “a few hundred examples” and get a specialized agent that recursively improves in hours instead of weeks.
Consider a workflow where the cost of a wrong answer is non-linear, for example, a compliance decision, a customer refund, or an incident response playbook. A base model that is usually right can still be unusable if the remaining failures cluster in high-severity edge cases. Poetiq’s pitch is that a harness can systematically probe, verify, and recombine the model’s latent knowledge to thin the tail of errors while also controlling cost.
Poetiq is positioned as an intermediate layer between foundation models and customer applications. An agent generator that can be called whenever a new model appears or a new workflow needs to be mastered.
Poetiq has demonstrated its approach on benchmarks that stress abstract reasoning (ARC-AGI), deep knowledge extraction with and without tool use (Humanity’s Last Exam), and short-form factuality / hallucination resistance (SimpleQA Verified).
Endurance rests on a meta-advantage. If Poetiq’s harness is truly model-agnostic and fast to retarget, then every new frontier model release becomes an opportunity.
Why This Works Now
The frontier models became good enough (and cheap enough via APIs) that the bottleneck shifted from raw capability to extraction. Getting consistent, verifiable reasoning out of a model without months of retraining.
Enterprises have experimented with GenAI heavily, but many deployments stall because the systems don’t learn inside the workflow and don’t reliably adapt to context. That gap is the opening for a meta-system that can rapidly create task-specific reasoning strategies without a new training run.
Why hasn’t this been built before now? Two reasons. First, older models weren’t worth wrapping: if the base capability is weak, orchestration mostly just rearranges error. Second, the traditional improvement lever (RL post-training) is slow and expensive. Poetiq argues it requires millions of data points and is impractical for all but a handful of companies.
In the early LLM wave, apps often meant chat interfaces and thin wrappers. The next layer was RAG and tool use. More recently, benchmark progress in hard reasoning tasks has been driven by test-time adaptation and more sophisticated reasoning systems rather than scale alone. ARC Prize’s ARC-AGI-2 framing: “Scale is not enough,” and the benchmark is designed to demand new test-time algorithms and efficiency, not just bigger models.
Recent trends that make this possible: API-first access to multiple frontier model families makes a model-agnostic orchestrator economically feasible. Cheaper and faster evaluation loops make learned test-time reasoning and systematic harness search practical. Enterprises increasingly prefer off-the-shelf solutions from incumbents when internal POCs fail, creating a distribution channel for layers that sit on top of model providers.
From Benchmarks to Budgets
If Poetiq is right that most enterprises can’t get reliable ROI from GenAI without better reasoning and learning loops, then the addressable market is a meaningful slice of the rapidly growing AI software stack.
Poetiq aims at two adjacent buyers. Teams building AI systems (product/engineering/research) who already have access to frontier models and need higher task performance per dollar. Enterprises that want GenAI to move beyond productivity tools into workflow-integrated systems with measurable P&L impact.
Poetiq is trying to define a new market: a meta-system that optimizes systems around models rather than building models. This resembles a new layer in the stack, call it reasoning optimization / harness generation, sitting somewhere between agent frameworks (tools to wire prompts together) and model training (changing the weights). The market is young enough that TAM math is necessarily approximate and should be treated as a sensitivity.
We do not provide a clean market category for reasoning harnesses, so we anchor on Gartner’s AI spending breakdown as a proxy for the adjacent software markets Poetiq would sell into. We treat these as upper bounds rather than precise definitions.
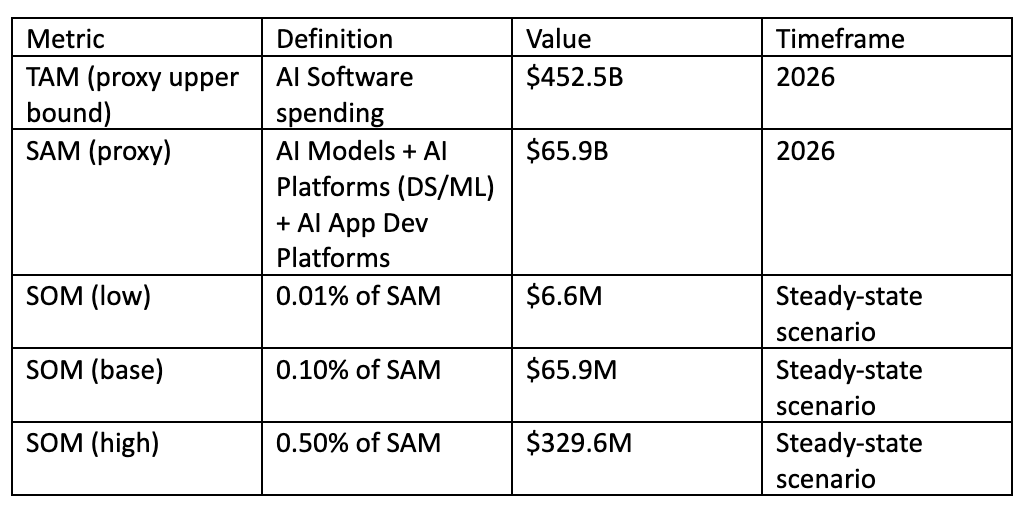
Important caveats:
Gartner’s categories are broad and include many products unrelated to Poetiq
Poetiq could be priced more like consumption (cost per task) than subscription (ARR), which changes the mapping
Poetiq’s long-term positioning (offering it for free in the future) suggests a strategy that might trade product revenue for ecosystem or research goals, but pricing intent is not clearly disclosed
The Alternatives: Prompting, RAG, Training
Poetiq competes less with a single vendor and more with a menu of good-enough workarounds. Prompting, RAG, and post-training. And with the frontier model providers who may bundle similar capabilities over time.
Direct competition (closest functional overlap) includes systems that orchestrate multi-step reasoning and verification around LLMs, including multi-model ensembles and agentic harnesses. Poetiq benchmarks against multi-model systems such as Zoom AI on HLE-with-tools, and against strong reasoning-model baselines on ARC-AGI-2.
Indirect competition is broader. Agent/orchestration frameworks (helpful wiring, but typically not a learned improvement loop). RAG and knowledge tooling. Fine-tuning and RL post-training services. And bundled agentic features shipped inside incumbent enterprise software.
Poetiq’s plan is to avoid head-to-head competition with base model vendors by riding them. The company argues it can integrate new models quickly and use its meta-system to discover task-specific reasoning strategies within hours of a model release. That gives it a plausible niche. Being the fast-moving optimizer that customers can keep constant while swapping underlying models.
Poetiq’s competitive advantages:
Model-agnostic positioning and rapid integration cadence
Data-efficiency: a few hundred examples rather than massive tuning datasets
Demonstrated benchmark performance on multiple reasoning/knowledge tests
Open-source credibility signal: Poetiq released an ARC-AGI solver repo intended to reproduce benchmark points, which could lower skepticism for researchers and some early buyers.
Inside the Meta-System
The product is a meta-system that automatically generates and improves task-specific agents (harnesses) around existing LLMs.
a meta-system that builds and improves agents
harnesses that orchestrate one or more models (and optionally tools like code execution/web search, depending on the benchmark track)
orchestrators meant to slot into larger systems
From the benchmark write-ups, the system appears to run iterative test-time reasoning loops, including learned strategies and self-verification.
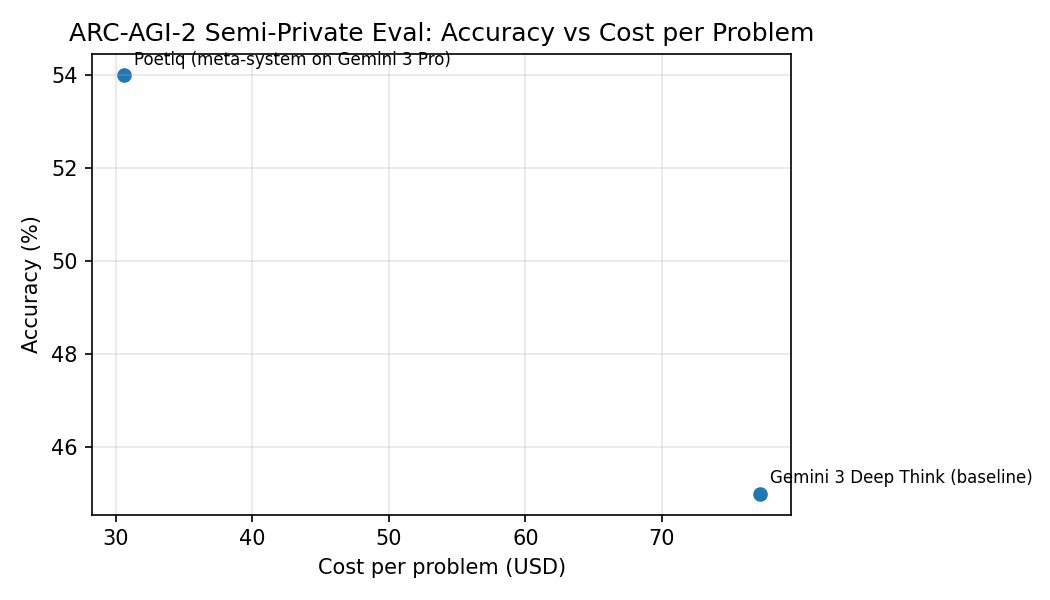
Poetiq’s strongest public validation comes from ARC-AGI-2, where the company reports an ARC Prize–verified semi-private score of 54% at $30.57 per problem, beating the prior best (45% at $77.16 per problem).

Poetiq also reports running the same harness with GPT-5.2 X-High on the ARC-AGI-2 public-eval set, reaching as high as 75% at “under $8 / problem. Beating prior SOTA by ~15 percentage points.
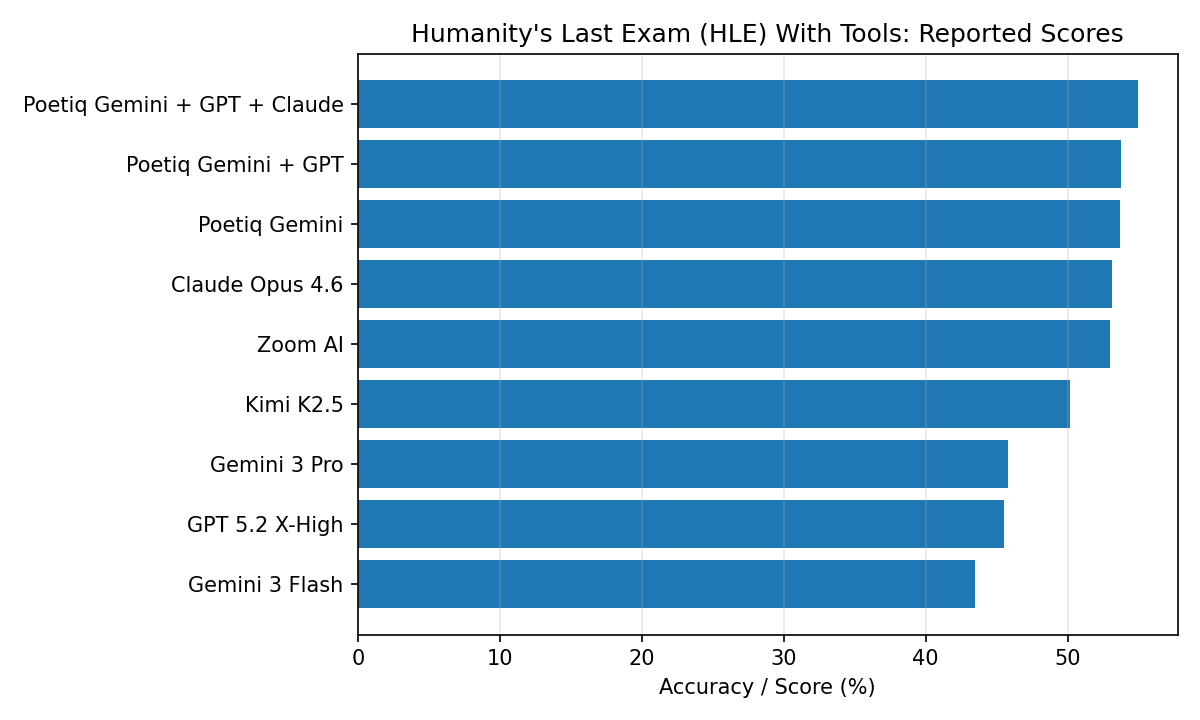
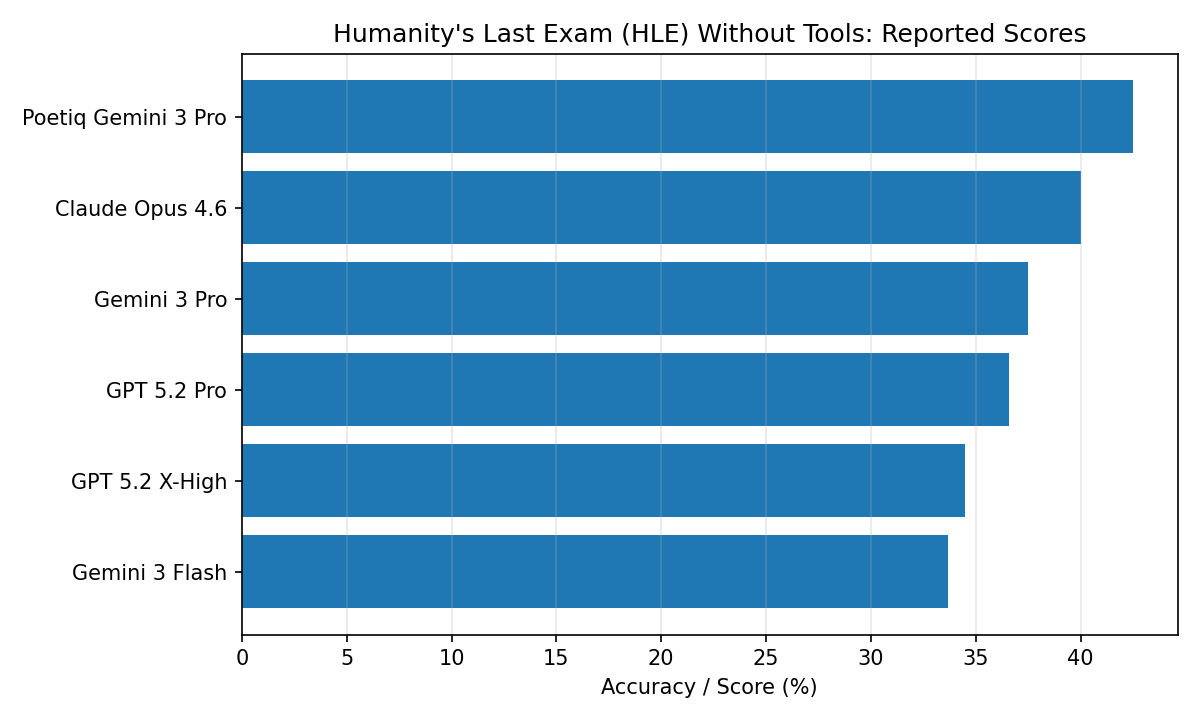
Beyond ARC-AGI, Poetiq shows improvements on benchmarks oriented toward knowledge extraction and factuality. On Humanity’s Last Exam (HLE), Poetiq reports a best score of 55.0% in the tools-allowed track using an ensemble harness across multiple model families, and a 42.5% result on the no-tools track using Gemini 3 Pro with a Poetiq harness.
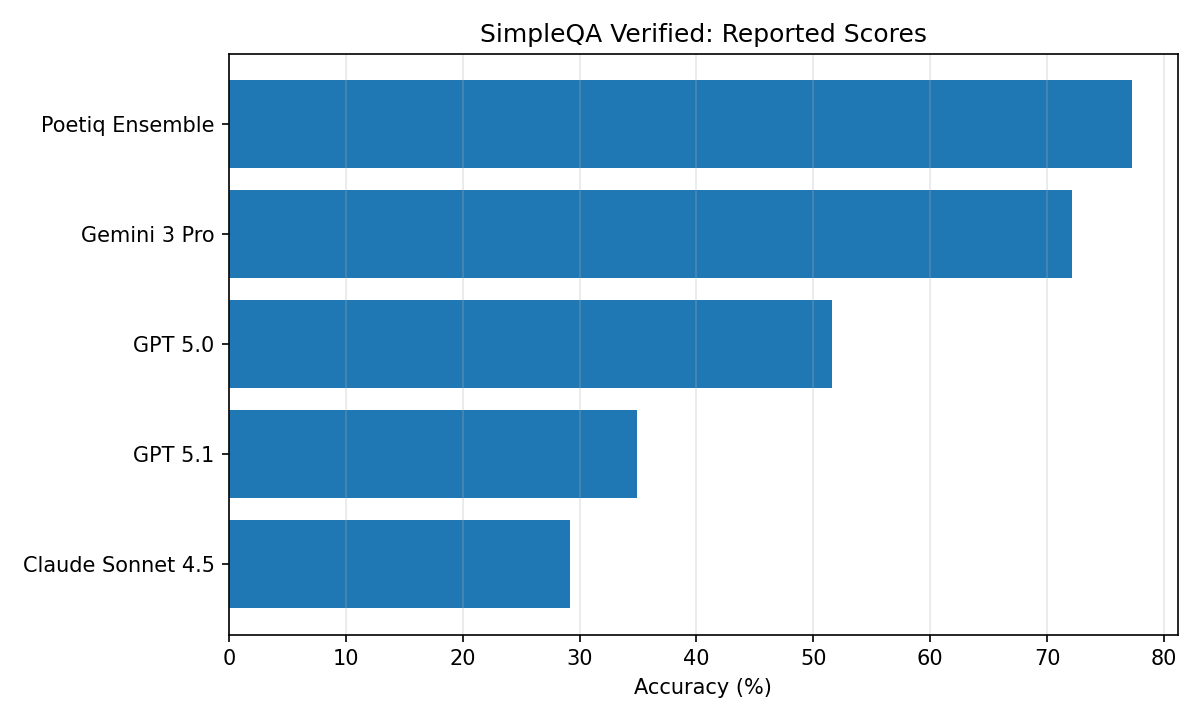
On SimpleQA Verified (a factuality benchmark), Poetiq reports that the same harness used for HLE without tools improves every model tested, and that a Poetiq ensemble reaches 77.3%.
Development roadmap: Poetiq’s published roadmap is directionally clear but operationally vague. In the ARC-AGI-2 verified post, the team lists three near-term themes:
Poetiq’s three near-term roadmap themes:
diversify tasks so the meta-system improves
integrate into larger systems
pursue long-horizon tasks without model tuning by improving knowledge extraction mechanisms.
Their seed round also lets them run recursive improvement loops around the clock and accelerate development of agents that dramatically outperform the underlying models.
How Poetiq Might Make Money
Poetiq appears to be building an enterprise-facing platform, suggesting a two-step path. First, prove the meta-system’s leverage on benchmarks (credibility). Second, convert that credibility into enterprise engagements where hard, expensive workflows become tractable. Compatibility with multiple model vendors could reduce vendor concentration risk and expand addressable customers.
The company hints at a potential free offering, but the company simultaneously runs an early access funnel and references working with early partners, suggesting at least some form of commercial engagement (paid pilots, enterprise contracts, or usage-based pricing). Without pricing disclosures, any specific model is speculation.
Based on Gartner’s observation that AI is often sold via incumbent software providers during 2026, one plausible distribution strategy is to integrate Poetiq as an optimization layer inside existing AI platforms or enterprise suites.
The Founders and Their Edge
Poetiq is founder-led by two long-tenured DeepMind/Google alumni, backed by a small, research-heavy team. Founded in June 2025 by co-CEOs Shumeet Baluja and Ian Fischer, both former Google DeepMind researchers. Baluja is credited with founding DeepMind’s mobile practice and starting its fundamental computer vision research group, with prior experience as CTO of Jamdat Mobile. Fischer joined DeepMind via the 2015 acquisition of Apportable, where he was co-founder and CTO.
OpenReview lists Ian Fischer as a Google researcher with a machine learning/information theory focus and a publication history spanning reinforcement learning and representation learning.
Beyond the founders, there’s a small set of technical staff of founding research scientists and engineers with experience at both Google/DeepMind.
Capital for Iteration
Poetiq raised $45.8M seed in January 2026. The round implies a meaningful cash position relative to early-stage headcount. Investors include Surface, FYRFLY, Y Combinator, 468 Capital, Operator Collective, NeuronVC, and HICO.
A reasoning-system company running recursive loops will likely spend heavily on compute and senior research compensation. The seed round is large enough to fund multi-year experimentation.
Reasoning as Infrastructure
In five years, the vision is Poetiq as a ubiquitous reasoning engine that plugs into enterprise systems and continuously improves task performance across domains. An optimizer that makes whatever model you use behave more like a reliable specialist.
A standardized evaluation-and-improvement pipeline that companies can point at any high-value workflow (support, compliance, operations, engineering) with a few hundred labeled examples and get back a versioned agent that is measurably more accurate than the base model, is cost-bounded, is auditable (tests, regression suites, failure-mode catalogs), and improves as it sees more tasks.
One strategic question is whether Poetiq remains a focused layer company (partnering broadly, staying lean) or becomes a platform with its own distribution and ecosystem.