
Plumbing for Agents: Inside Parallel Web Systems
How Parallel is turning the messy internet into structured, cited context.

Parallel builds the web‑infrastructure layer that lets AI systems reliably search, read, extract, and monitor the live internet at scale, with citations and confidence signals.
Parallel frames the web as a kind of public utility and argues that the next wave of users won’t be human. The core bet: as AIs become capable of operating software, they will consume and act on web information far more intensively than people do, and the web needs infrastructure that treats AIs as first‑class citizens rather than weird screen-scraping tourists.
The Pain: The Web Is Essential, Hostile, and Unstructured
Most agent demos assume the web is a friendly database. Production reality is less polite. If your workflow depends on the live internet: competitive intel, compliance checks, sales enrichment, support automation, deal sourcing, code research, you run into the same headaches humans have, plus a few new ones: websites change constantly, pages are optimized for human eyes, content is gated behind logins and cookie walls, rate limits are real, and the model must provide sources you can audit.
For many teams is getting an answer you can trust, cheaply, in a way that survives next week’s website redesign.
How this is addressed today:
DIY stack: stitch together search APIs + crawling + HTML parsing + PDF extraction + LLM prompts + caching.
“Browsing” features bundled in chat products or model platforms (useful for individuals; hard to productize at scale).
RPA / workflow automation tools with web connectors (brittle when the page changes; often human-in-the-loop).
Specialized vendors: data enrichment providers (good coverage in narrow domains; expensive and not general web).
Human research / ops teams (reliable, but doesn’t scale linearly with margin).
The shortcomings of current solutions:
Brittleness: screen-scraping breaks; selectors rot; anti-bot measures escalate.
Cost and latency: “agentic browsing” is slow and expensive when you drive a full browser for every task.
Trust gap: outputs without citations are unusable in regulated or customer-facing contexts.
Operational drag: building and maintaining a crawler/index pipeline is a full-time business.
Coverage gap: the most valuable pages are often behind logins, cookie popups, or dynamic rendering.
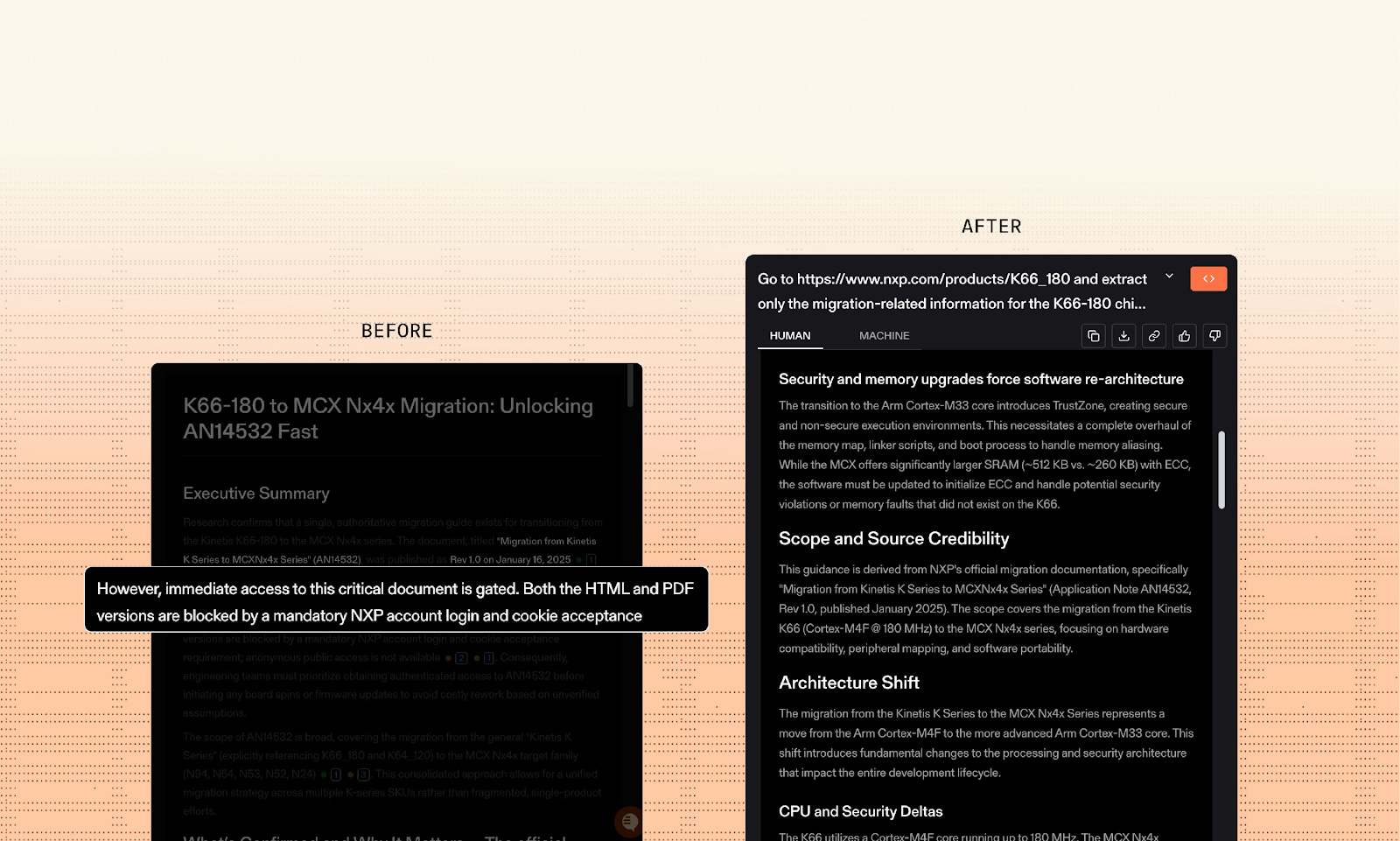
The Eureka: Turn the Internet into Token-Dense, Cited Context
Parallel treats the web as a first‑class data plane for agents, and packages the messy parts: crawling, indexing, extraction, synthesis, monitoring, and authenticated access, behind a small number of declarative APIs.
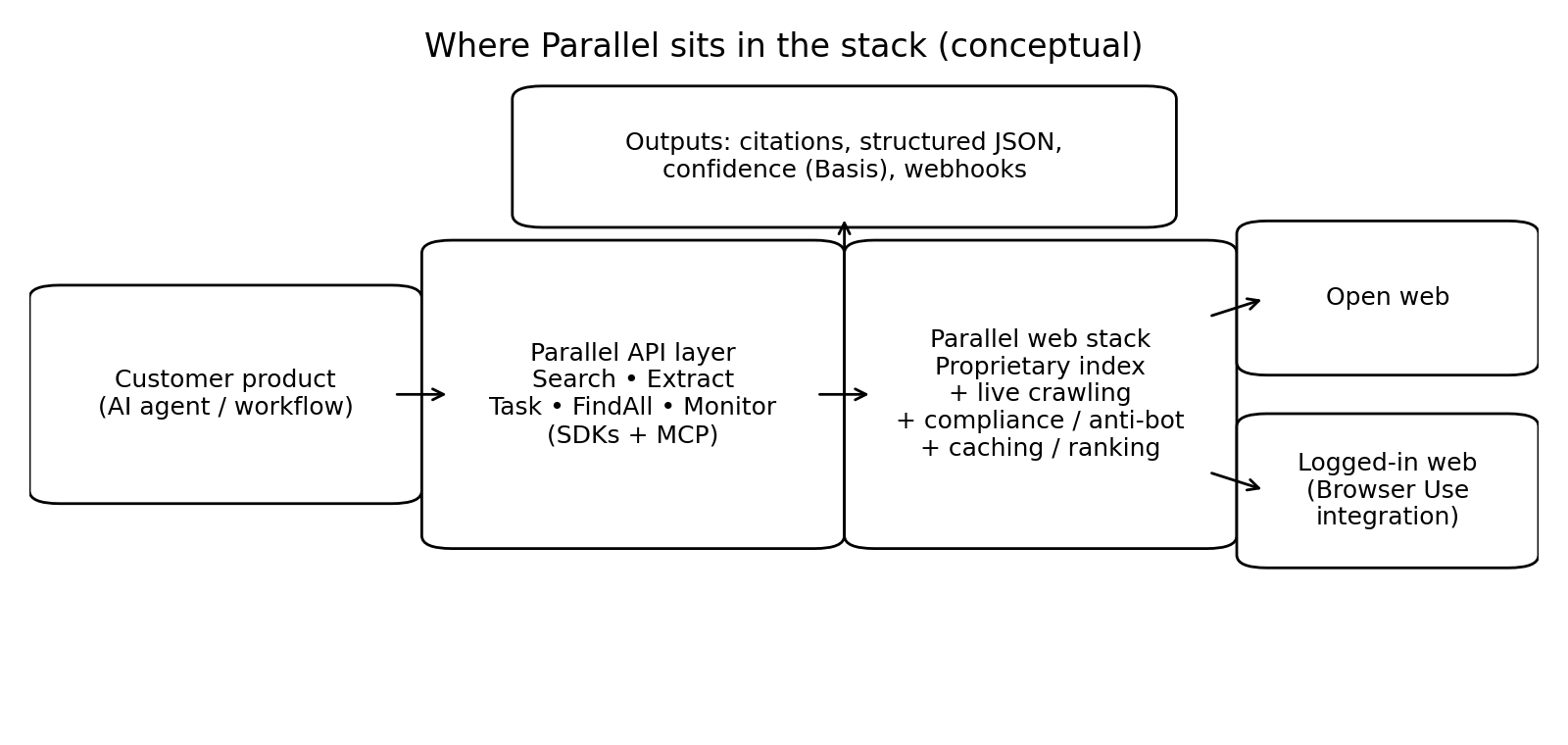
The company emphasizes three things that production teams actually care about:
Price‑performance knobs (processors): you can pay for faster/cheaper or deeper/more reliable work on a per‑request basis.
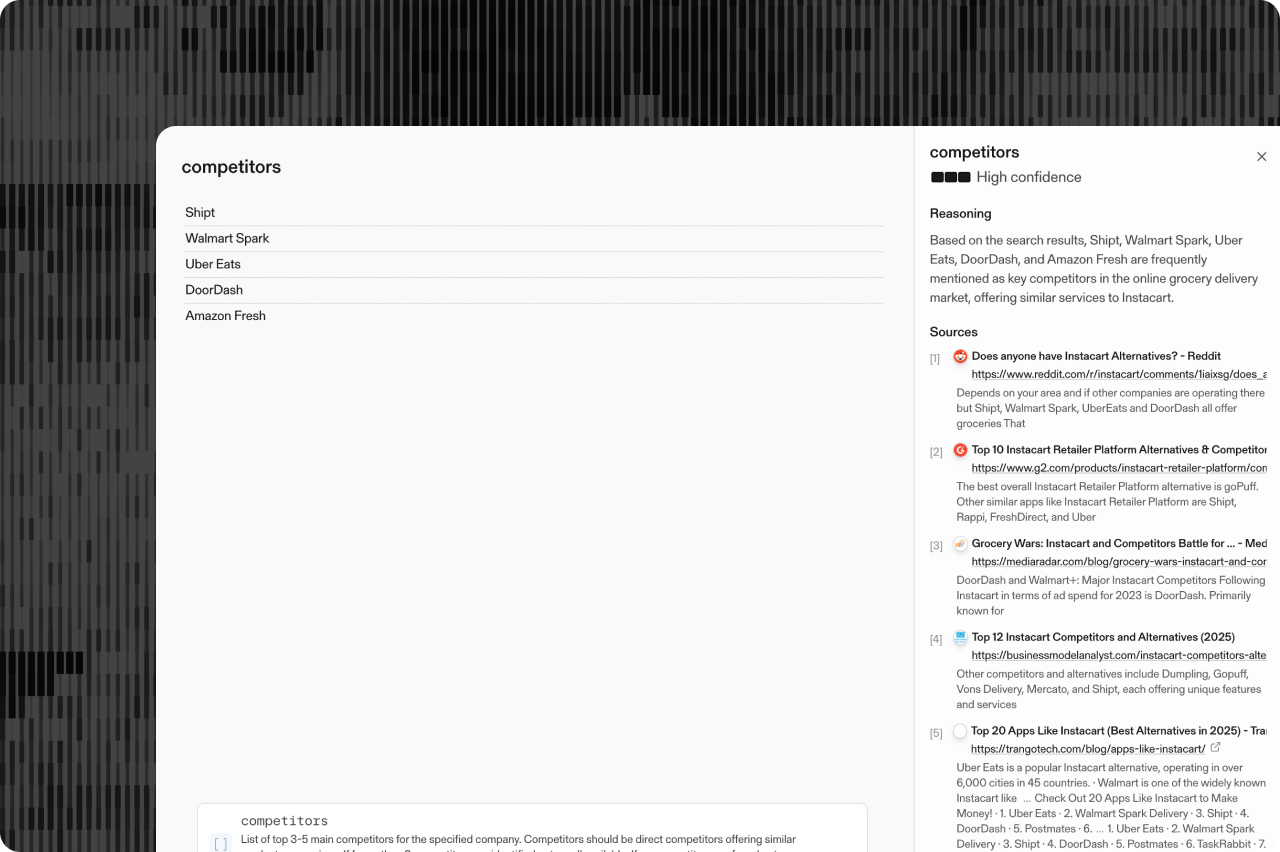
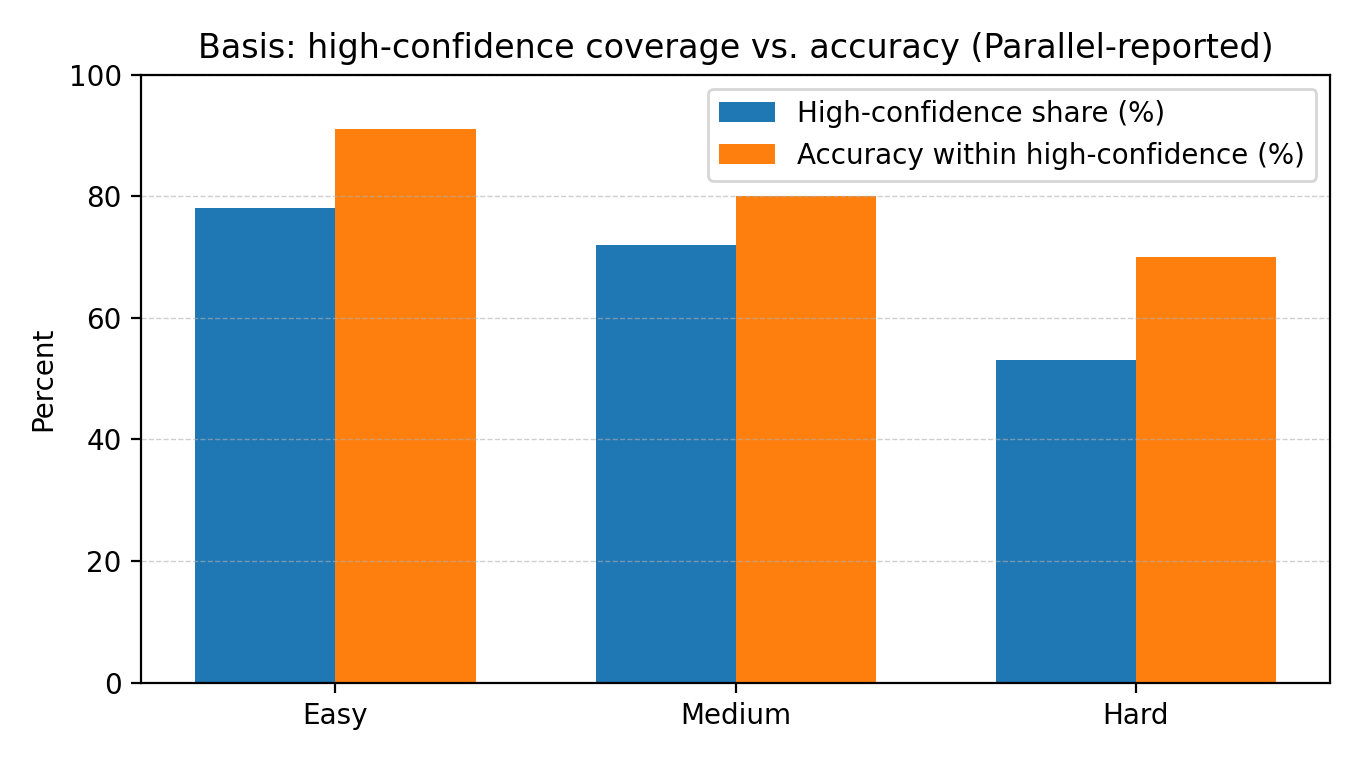
Verifiability: citations are first‑class outputs, and Basis provides calibrated confidence so you can triage or route uncertain results.
Machine-ready outputs: structured JSON extraction and bulk discovery (FindAll) reduce the manual glue work that makes many agent projects stall.
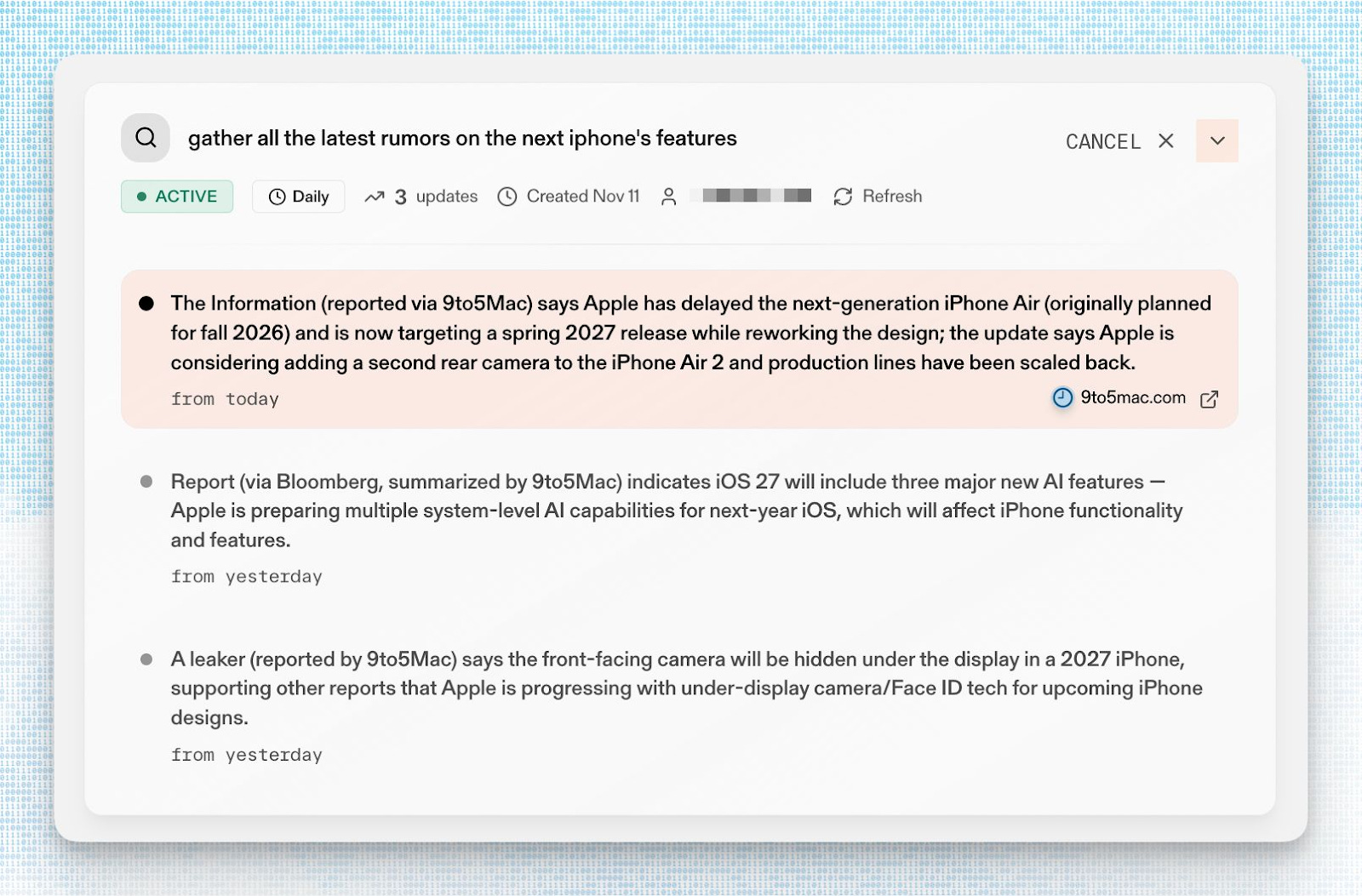
Parallel’s customers are people trying to ship workflows:
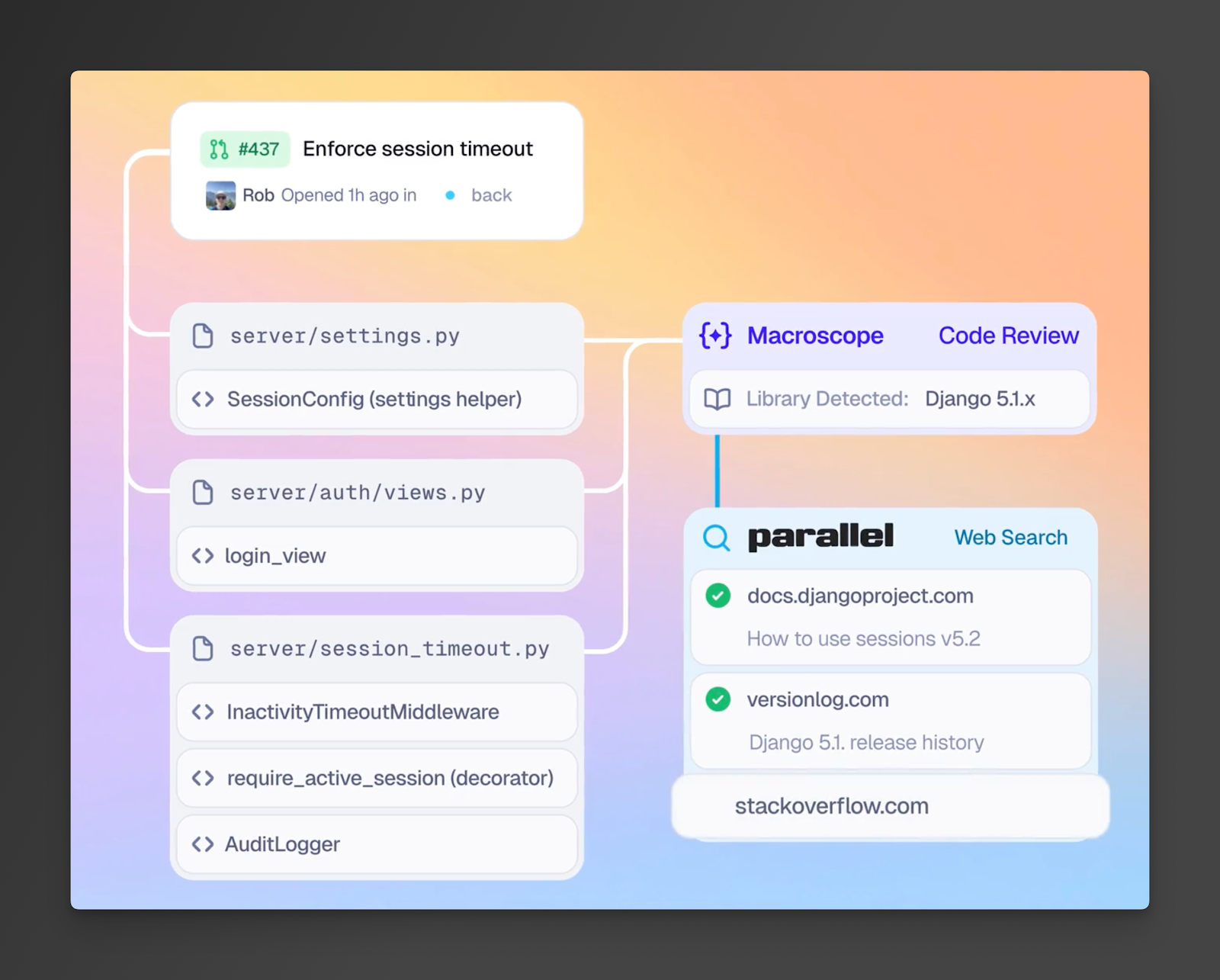
CRM enrichment and sales intelligence (e.g., Gumloop automation nodes for enrichment).
Agentic customer support and internal ops (e.g., Lindy’s assistants that can chat with the web).
Meeting and code research for developers (e.g., Amp’s developer-focused workflows).
Investment/real‑estate research (e.g., Day AI’s property analysis pipeline).
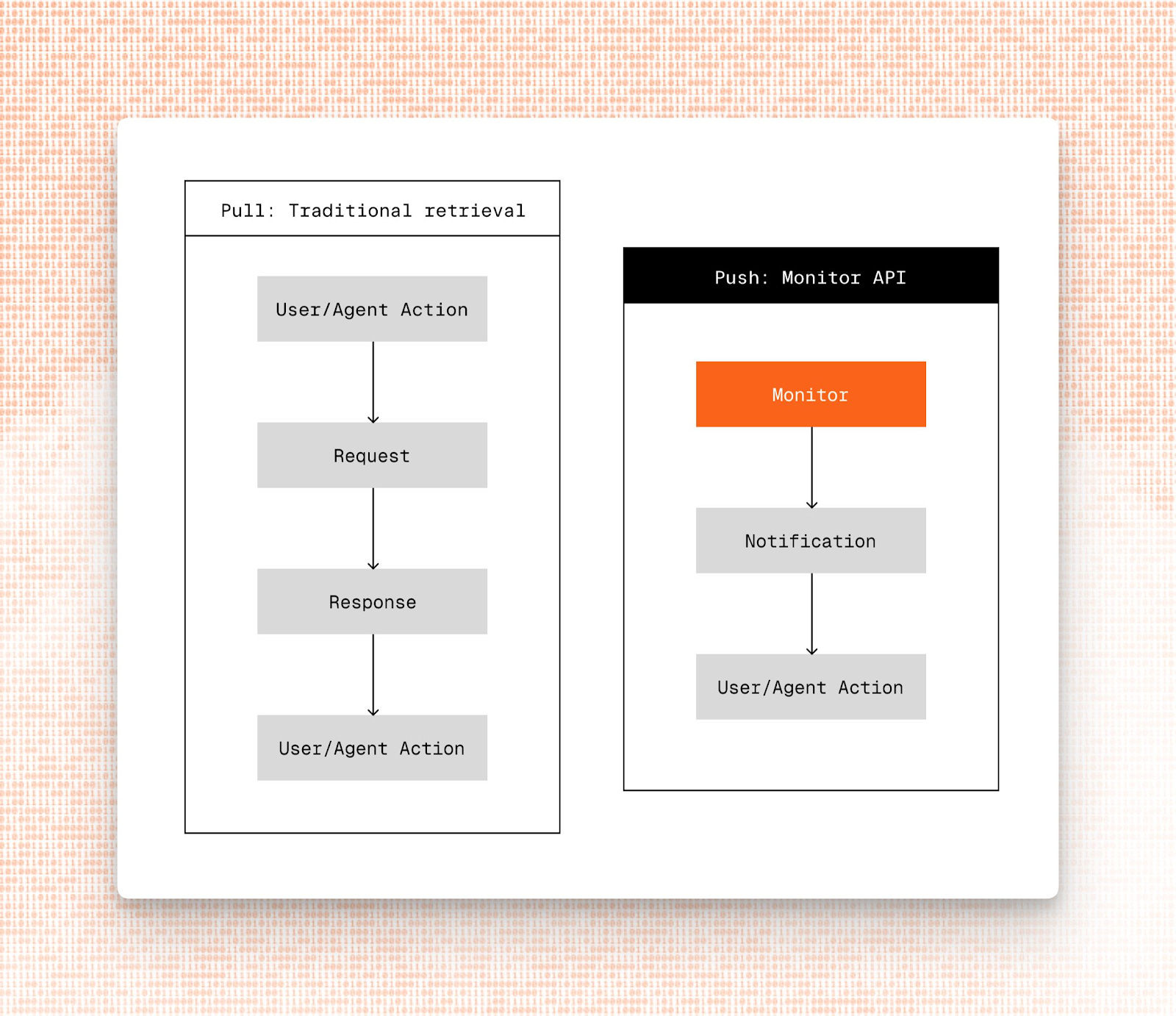
Competitive monitoring and alerts (Monitor API).
Parallel sits between an agent application and the web. It absorbs the web’s chaos (search, crawling, anti-bot, parsing, freshness) and returns structured, citeable outputs to the calling system.
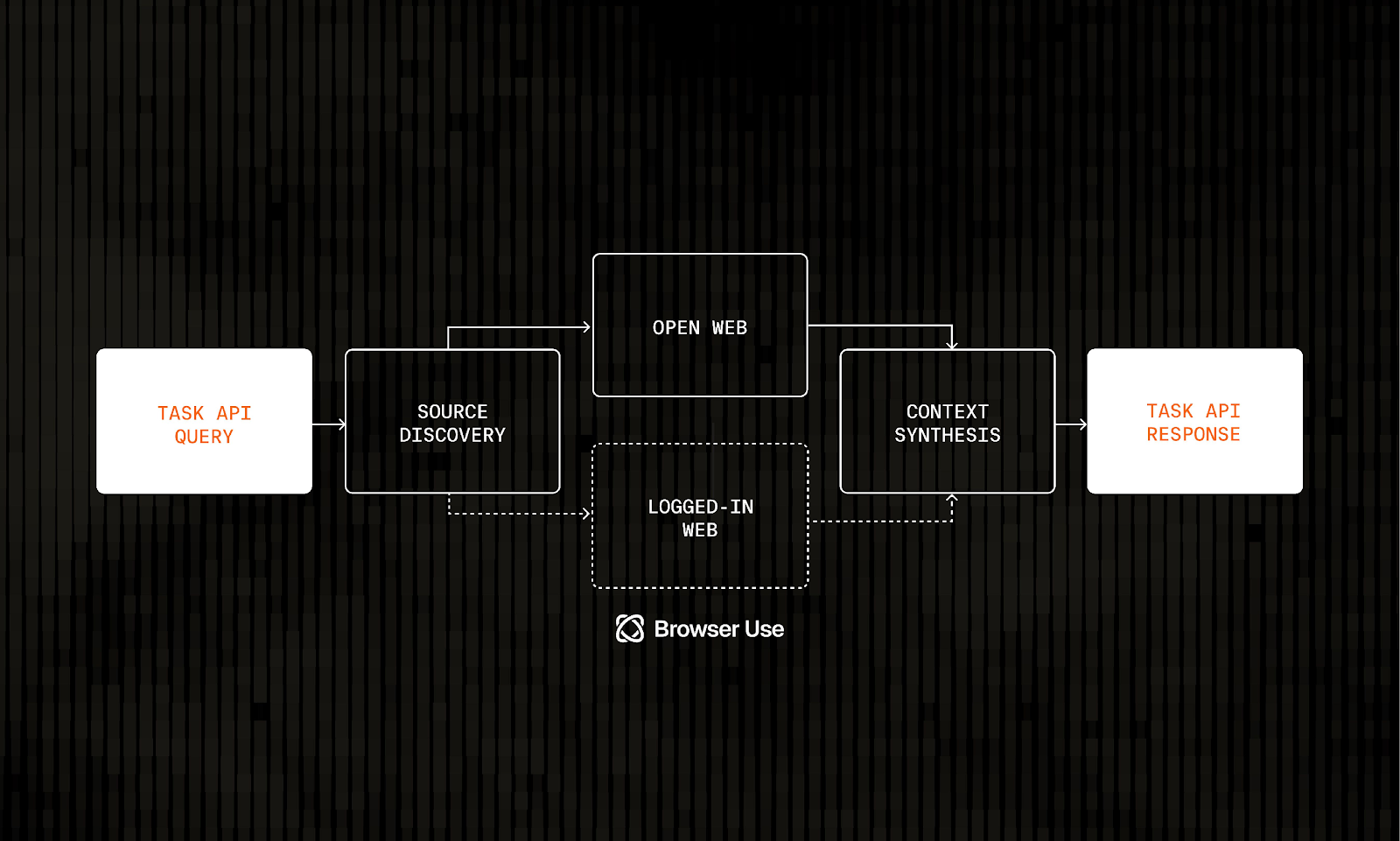
Timing: Agents Arrived; Infrastructure Didn’t
Agentic software became plausible (models can plan and use tools), but the web became more adversarial, creating a vacuum for a specialized, reliability-first web layer.
Until recently, the ROI was missing. Pre‑LLM, automation either lived inside structured systems (databases, APIs) or relied on brittle RPA screen scraping. Building a proprietary web index and an agent‑friendly retrieval layer is expensive, and the demand signal wasn’t strong enough to justify it. In 2024–2026, the demand signal flips: agent builders need web access as a core dependency.
Historical evolution of the category:
Search engines → human-facing results pages (great for people, awkward for machines).
Web scraping → bespoke pipelines for narrow needs (powerful but operationally costly).
RPA → UI automation for enterprises (useful, but fragile and often human-supervised).
RAG (retrieval augmented generation) → models citing internal docs and curated corpora.
Agent era → models expected to interact with arbitrary, changing websites (the messy part returns).
Trends that make Parallel’s solution possible now:
Models are now competent enough at tool use and synthesis to make ‘web + reasoning’ workflows valuable.
Standardized integration patterns (SDKs, serverless, MCP) lower adoption friction for developers.
Falling inference costs make usage-based ‘processors’ viable as a product knob.
An explosion of agent applications creates a new infrastructure buyer archetype (AI-native product teams).
At the same time, anti-bot and paywalls increased, making naïve scraping less viable, raising the value of a managed, compliant layer.
Parallel positions itself as the response to that shift: “web infrastructure for AIs.” The company the web to become harder to work with, hence investments in authenticated access and monitoring.
Market: The Agent Web Economy
Parallel sells to builders of agentic workflows. That includes:
AI-native product companies shipping agents to end users (e.g., assistant apps, research tools).
Automation platforms and workflow tools that need live web research/enrichment as a building block.
Enterprises building internal agents for sales ops, compliance, procurement, security, and competitive intelligence.
Service providers / BPOs embedding web research into processes.
Parallels’ customers:
Amp (developer assistants).
Starbridge (web intelligence workflows)
Lindy (AI assistants with ‘chat with the web’)
Day AI (real-estate / private market research)
Gumloop (automation nodes for web research + enrichment)
Macroscope (data pipelines / monitoring)
Manus
Clay, Sourcegraph, Replit, Attio
Genpact
A conservative way to think about Parallel’s TAM is: the portion of agent software spend + web scraping spend + open‑web search spend that is allocated to web retrieval, extraction, and monitoring infrastructure.
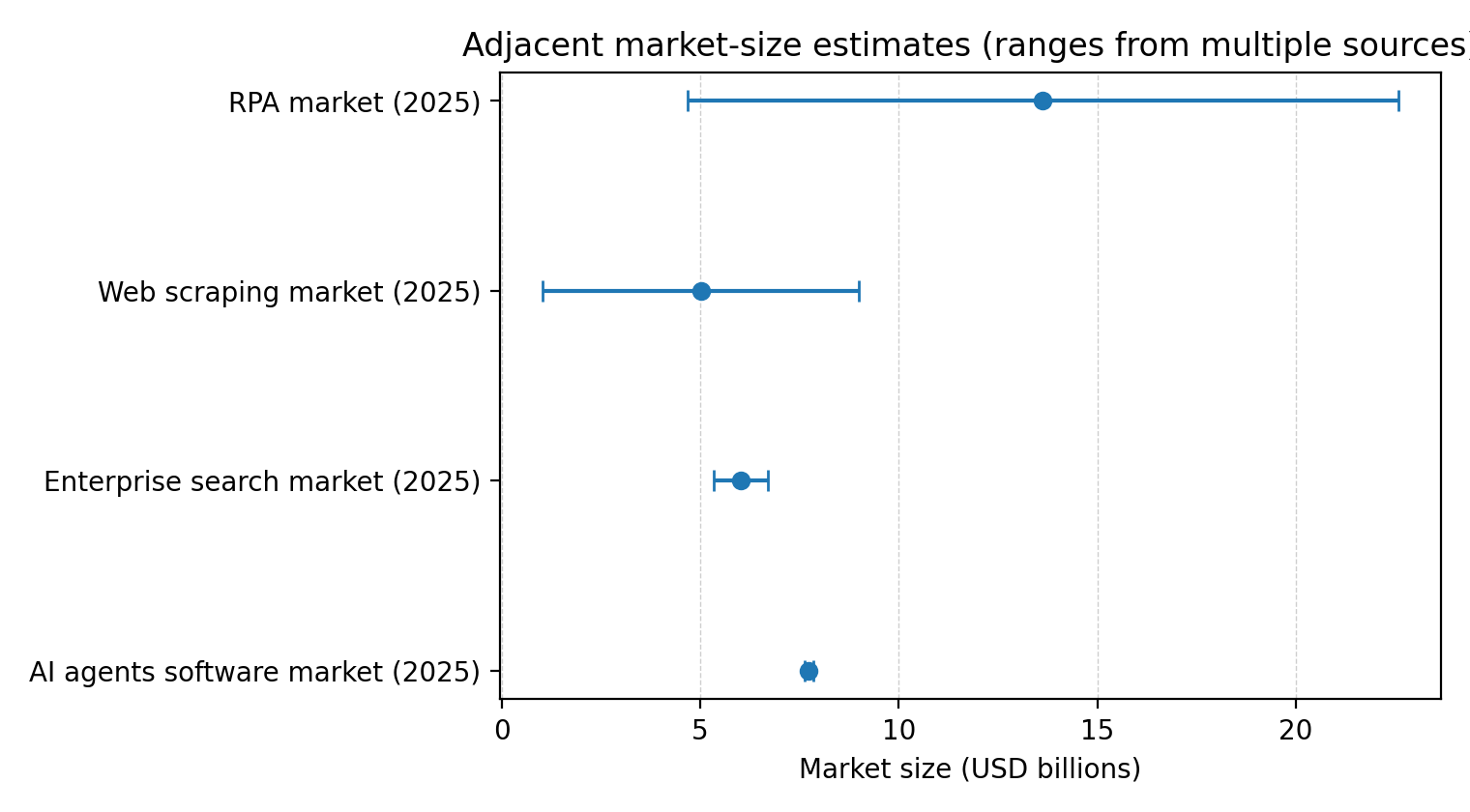
Using published 2025 estimates:
AI agents software market: ~$7.6–$7.8B.
Web scraping services: estimates range widely (~$1B to ~$9B).
Enterprise search: ~$5.3–$6.7B (mostly internal; only a slice is open web).
RPA: a broader umbrella with very wide estimates (~$4.7–$22.6B).
If we assume (illustratively) that 10–20% of AI agents spend, ~10% of enterprise search spend, and a meaningful share of web scraping spend maps to agent web infrastructure, you land in a TAM on the order of a few billion dollars today, with significant upside if agent adoption compounds.
A bottoms‑up SAM can be approximated from buyer counts × plausible annual spend. The relevant buyers are:
AI-native agent builders and automation platforms.
Mid‑market and enterprise teams building internal agents.
Illustrative math: if 5,000 AI‑native teams spend ~$25k–$100k/year on web infrastructure, that’s $125M–$500M. If 2,000 enterprises spend ~$100k–$500k/year, that’s $200M–$1B. So a reasonable SAM range might be roughly $300M–$1.5B.
SOM is about execution. If Parallel becomes a default layer for agent builders, capturing 5–15% of the SAM over ~5 years is plausible in a strong execution scenario. That would imply tens to a couple hundred million in annual revenue. If bundling pressure or web lock-down intensifies, the attainable SOM could be much smaller.
The Arena: Search, Models, and “Good-Enough” Browsing
Direct competitors (agent-focused web search / research):
Exa (web search API for AI).
Perplexity (Deep Research; Sonar models and research flows).
Model-platform ‘browsing’ offerings (OpenAI deep research; Anthropic web search; Google Gemini grounding).
Specialized ‘web for LLMs’ APIs (e.g., Tavily-style search APIs; SERP proxies).
Indirect competitors / alternatives:
Build it yourself: crawl + index + parse + rank + prompt + monitor (a full-stack cost).
RPA vendors (UiPath, Automation Anywhere, etc.) for brittle but functional web automation.
Data vendors that sell structured datasets (ZoomInfo-like enrichment; paid databases).
Humans (research teams, VA services, offshore ops).
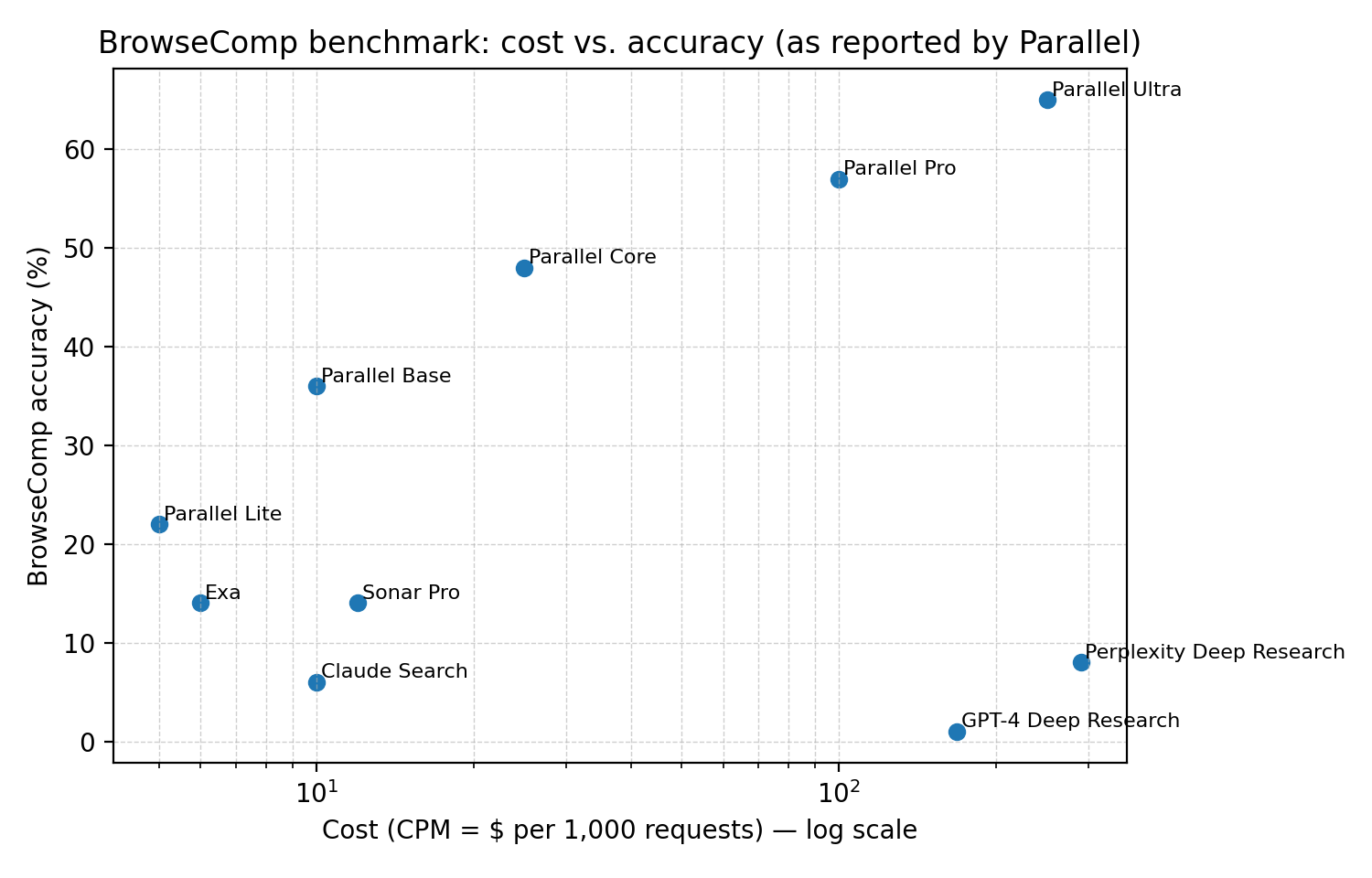
Parallel’s visible strategy is to live on the efficiency frontier: better answers per dollar and per second, with outputs you can audit. They show comparative benchmarks (e.g., BrowseComp) and emphasize knobs (processors) that let teams tune cost vs. depth.
Parallel’s defensibility:
Proprietary web index + retrieval stack.
A product suite that maps to real workflows (search, extract, bulk discovery, monitoring, authenticated access).
Verifiability features (“Basis” confidence + citations) that reduce the cost of human review.
Distribution partnerships (Vercel AI Gateway; cloud marketplaces) that make adoption a toggle.
A visible benchmarking culture that forces continuous improvement.
Where the advantage is fragile:
If a dominant model provider ships equivalent web retrieval with similar reliability at near‑zero marginal price, stand‑alone APIs get squeezed.
If publishers and sites broadly block agent traffic, the value shifts from ‘index quality’ to ‘access agreements.’
Benchmarks are imperfect; teams can optimize for leaderboards in ways that don’t generalize (classic Goodhart’s Law).
The Stack: Search → Extract → Research → Monitor → FindAll
Parallel’s products are delivered primarily as APIs (developer-first) and surfaced via SDKs and integrations (e.g., MCP servers, Vercel AI Gateway). Pricing also suggests a clean internal segmentation: “Web Tools” vs “Web Agents.”
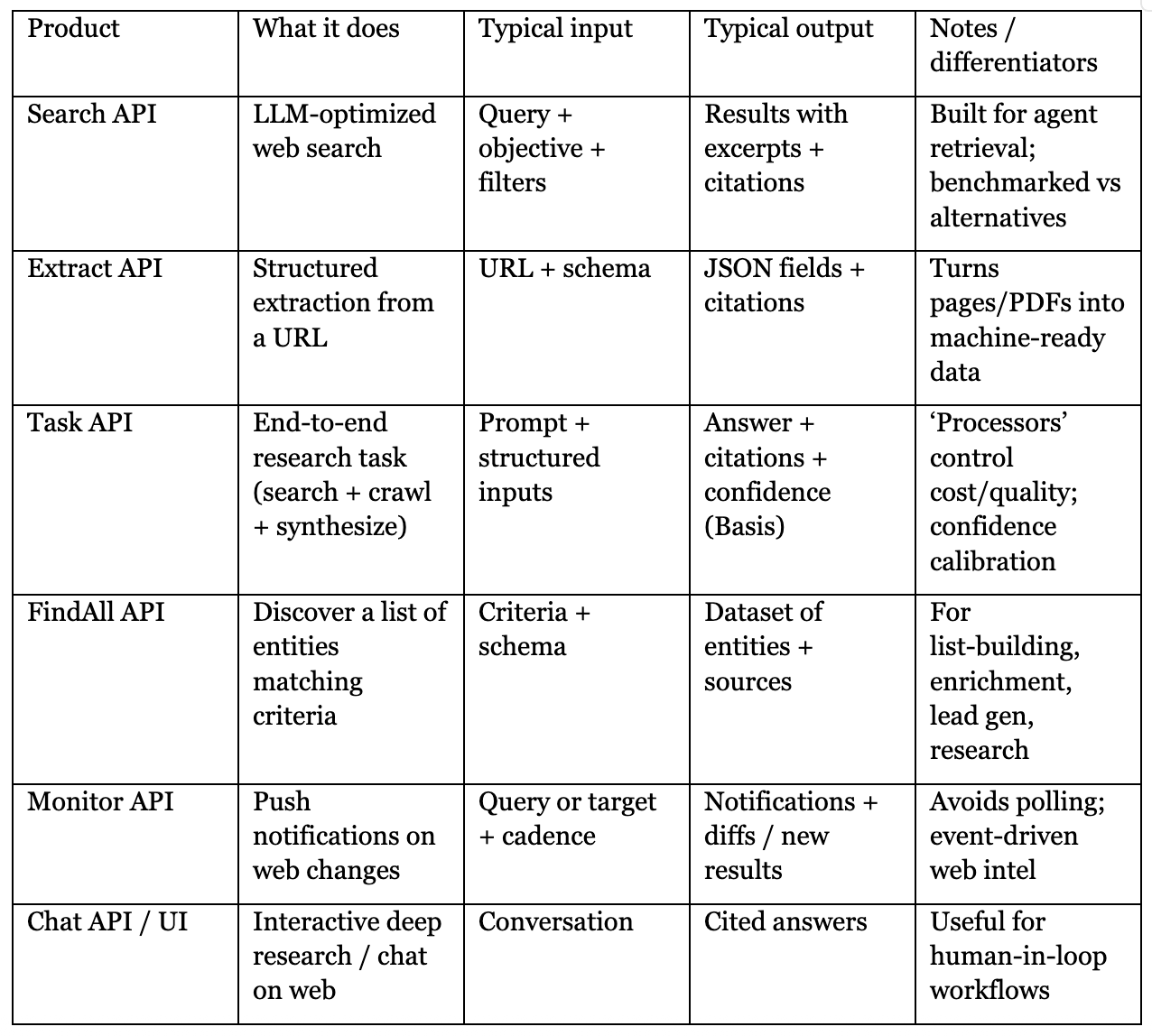
With Basis, the system reports calibrated confidence so teams can route low-confidence outputs to review or fallback.
How It Makes Money: Billing the Bot
Parallel’s business model is usage-based API pricing with enterprise upgrades. The company sells web capabilities as metered units (requests, tasks, entities, notifications). If Parallel can keep gross margins healthy, this is a compounding model: customers build it into core workflows and then scale volume.
Revenue model:
Self-serve API usage (metered pricing).
Enterprise contracts (likely custom limits, SLAs, dedicated support, volume discounts).
Channel distribution via gateways/marketplaces (Vercel AI Gateway, AWS Marketplace, cloud integrations).
Parallel’s public pricing:
Search + Extract bundle: $1 / 1,000 requests.
Task API: tiered by processor (Lite $5 CPM up to Ultra 8x $2,000 CPM).
FindAll: priced per 1,000 entities (Base $5; Pro $25).
Monitor: $5 / 1,000 queries + $5 / 1,000 notifications.
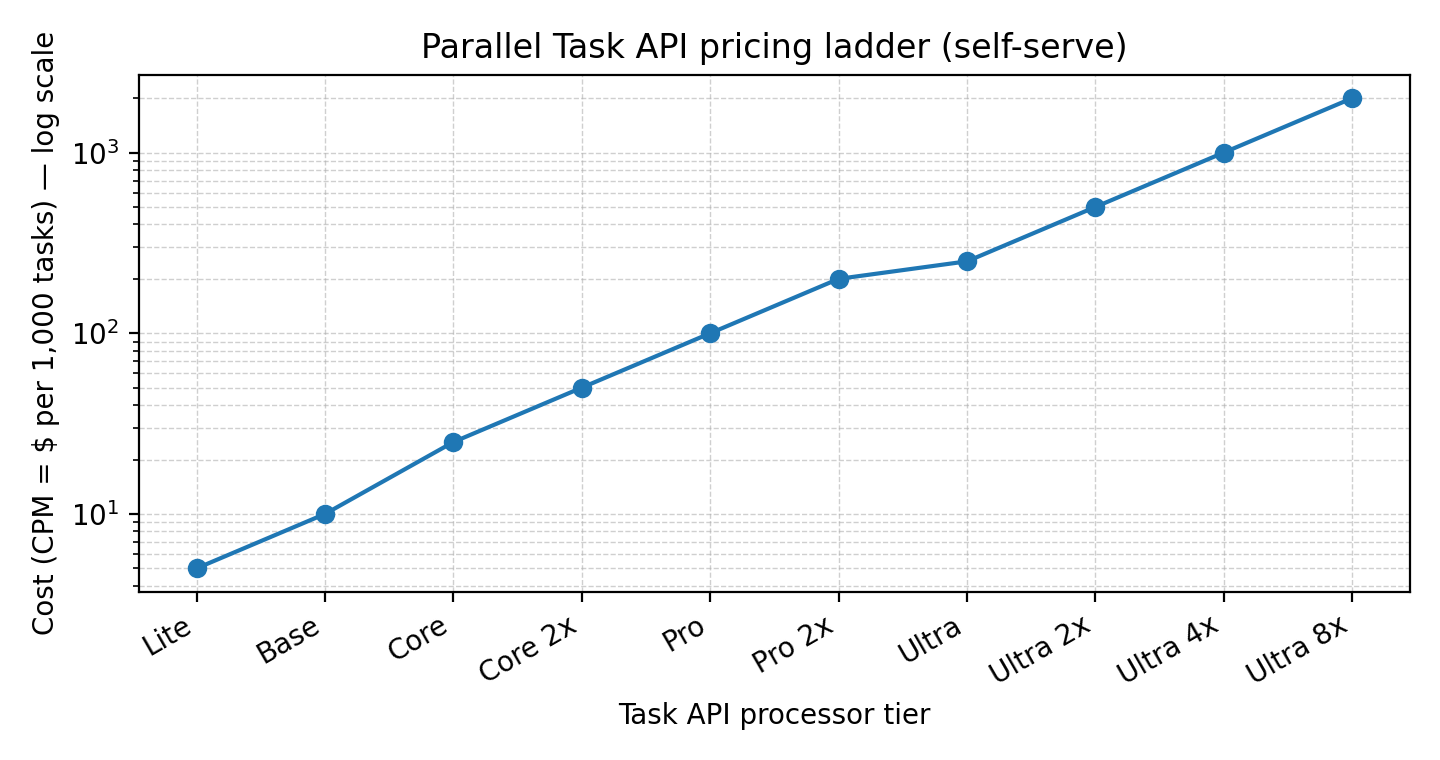
If we intuit the unit economics from publicly available information:
A product that runs 5M Search+Extract requests/month costs ~$5k/month.
A workflow that runs 1M Task API ‘Core’ tasks/month costs ~$25k/month.
A heavy enterprise deployment could easily run tens of millions of tasks/requests monthly, implying six-figure annual spend.
The go-to-market is hybrid:
Bottom-up adoption: developers start self-serve, then expand usage as workflows prove value.
Platform distribution: Vercel AI Gateway makes Parallel an option inside existing inference plumbing.
Enterprise motion: cited Fortune 100/500 usage suggests direct selling for larger contracts.
Ecosystem integrations: MCP servers and tool frameworks reduce integration friction.
The People: Builder DNA + Scientific Method
Parallel is founded by Parag Agrawal (former Twitter CEO). Beyond the CEO is a founding group with backgrounds spanning Twitter, early Google, Stripe, Airbnb, Chime, Waymo, and Kitty Hawk—i.e., people who have seen both consumer-scale systems and reliability-driven infrastructure. Parallel has about ~50 employees at the time of the Series A (Nov 2025).
Parallel’s team composition suggests an infrastructure-first culture, with marketing that leans hard on benchmarks and calibrated confidence. Systematic advantage comes from measurement, iteration, and ruthless feedback loops. Publishing benchmarks (even imperfect ones) is a way of committing to that loop in public.
The Numbers: What We Know, What We Don’t, What Matters
Press coverage reported a $100M Series A at a ~$740M valuation (Nov 2025). Investor writeups also reference an earlier ~$30M round in early 2024. They do imply substantial runway to build and maintain an index-heavy platform.
Below is a scenarioP&L structure, built from public pricing and typical infrastructure cost structures. Numbers are illustrative ranges.
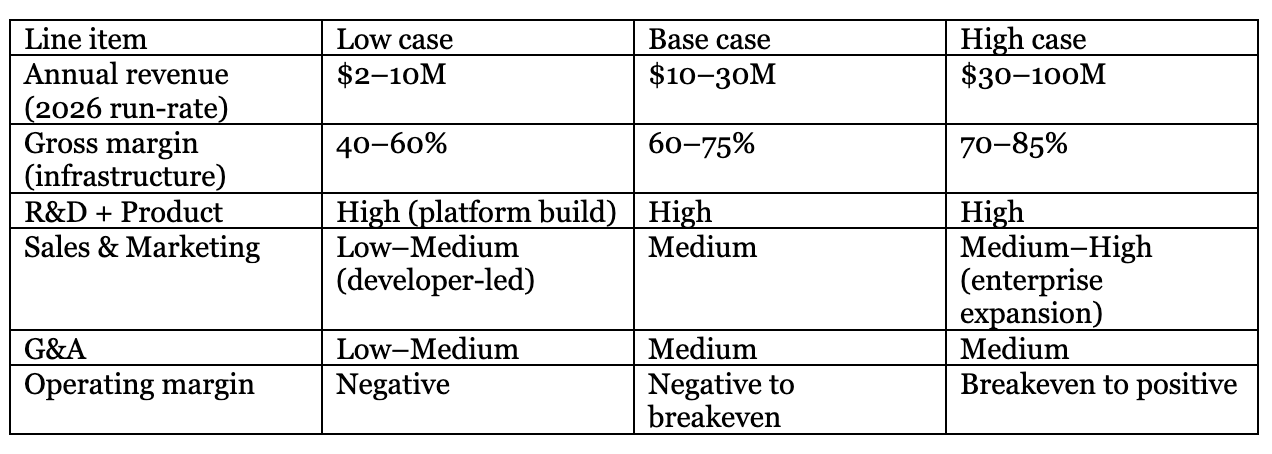
If Parallel’s value proposition continues to hold (better answers per dollar) and usage grows with customer workflows, revenue scales with volume. The key unknown is gross margin: crawling + inference + anti-bot handling can be expensive, and the company is competing in a market where customers expect costs to fall over time.
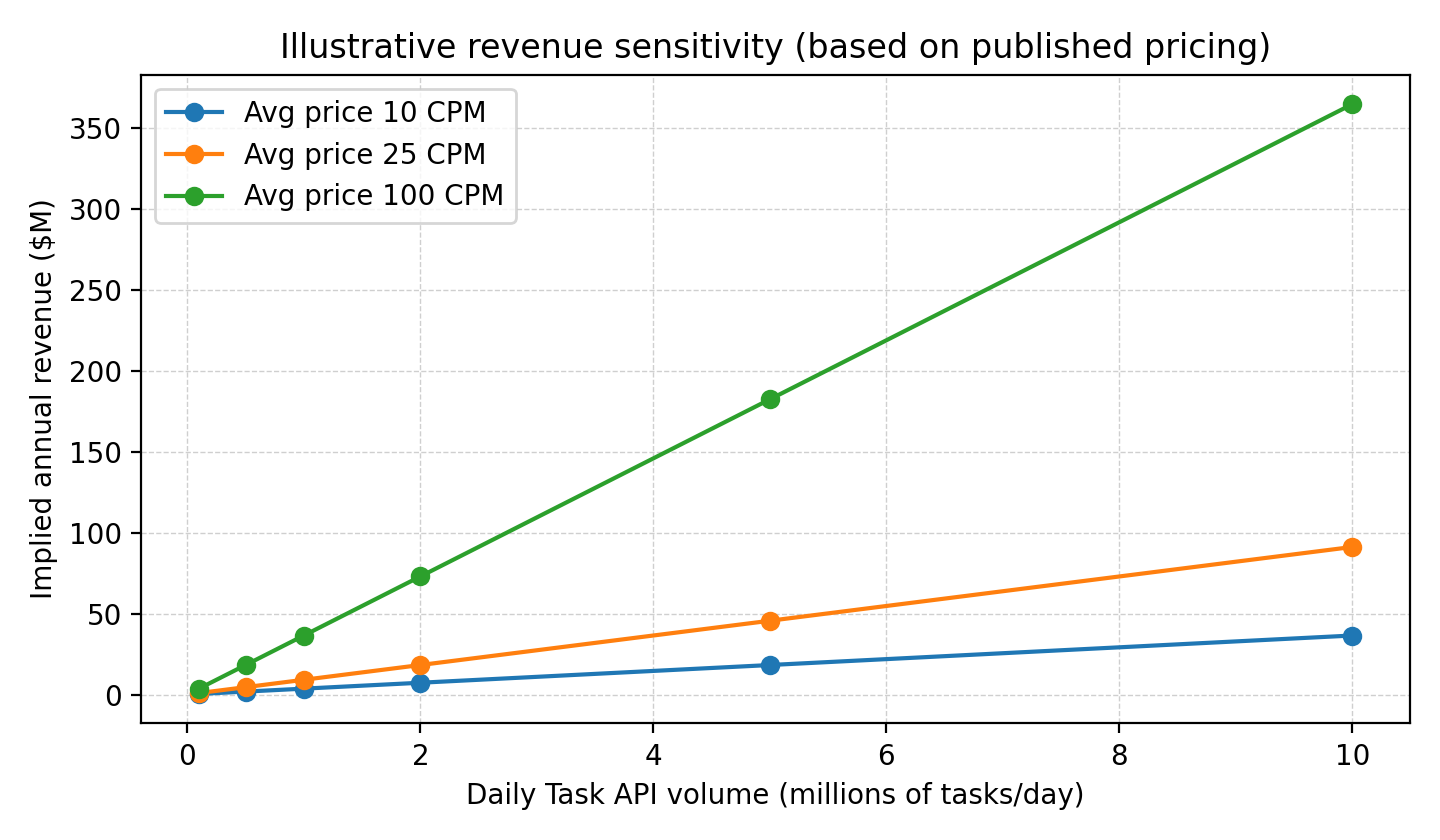
One public clue is Parallel’s claim that it powers “millions of research tasks daily.” If we (very roughly) map ‘research tasks’ to Task API calls and apply the published CPM ladder, we can create a revenue sensitivity curve. This is not a revenue estimate, just a way to understand the scale of the machine.
The Endgame: A Machine-Readable Web That Stays Open
In the best case, Parallel becomes the default web layer”for agentic software the way Stripe became the default payments layer for internet commerce. Not because it’s sexy, but because it’s reliable, ubiquitous, and embedded.
That vision is already implicit in their framing of the web as infrastructure and in the breadth of their product suite: search, extraction, task-level research, bulk discovery, monitoring, and authenticated access.
Plausible five-year outcomes:
A widely adopted API standard for agent web retrieval (Parallel becomes a default dependency in agent frameworks).
A richer web interaction surface: beyond reading to acting (forms, submissions, transactions) in compliant ways.
A ‘publisher-compatible’ access model (partnerships, paywalls, authentication) that keeps the web economically alive.
A compounding data advantage: feedback loops from billions of requests improve ranking, extraction, and confidence calibration.
What would make that vision fail (pre-mortem):
Web access becomes pay-to-play and Parallel can’t secure enough partnerships.
The feature is bundled away by hyperscalers/models at effectively zero price.
Reliability stalls: accuracy doesn’t improve fast enough relative to customer expectations.
Regulatory or legal constraints make generalized crawling too risky for customers.