
Mercor's Master Plan
From training-data contracts to hiring for all work.

Mercor positions itself as a two-sided marketplace for expert labor used to train and evaluate frontier AI systems, and, increasingly, as the benchmark-setter (APEX) that defines economically valuable work for models.
Its wedge is high-velocity, high-trust human-data production (rubrics, evals, preference data, domain-specific workflows) where experimentation speed, data security, and annotator quality dominate.
The core loop: build the expert network → generate differentiated data + benchmarks → benchmarks shape demand and budgets → demand funds more expert throughput.
Scale is already non-trivial: Mercor reports paying $1.5M-$2M/day to experts, and an average pay rate of $95/hour.
Expert Judgment Doesn’t Scale
Mercor’s primary customer is the team building or fine-tuning AI systems that needs human-generated signal - high-precision rubrics, evaluations, and domain-specific judgments. The pain is threefold: (1) non-expert labor caps model capability, (2) iteration cycles slow when data workflows are slow, and (3) data security and IP risks rise when opaque labor touches sensitive artifacts.
Mercor describes two default options: outsource to vendors (the Black Box) or build an internal human-data team. Outsourcing can be slow to iterate and opaque on cost/quality, and it can create data security concerns. Building in-house improves control but creates fixed costs and operational burden (sourcing, vetting, performance management, churn).
Turning Work into Signal
Mercor’s core insight is that the scarcest input to better AI is credible judgment. The product forces expert judgment into reviewable artifacts (rubrics, eval sets, structured workflows) that can be audited and iterated. In Brendan Foody’s words, “the best analog is a rubric,” and when rubrics fail, experts can generate preference data (RLHF-style).
Mercor’s Open Box pitch bundles three properties that rarely coexist: (1) expert-level talent quality, (2) iteration speed via hourly pricing and rapid staffing changes, and (3) transparency/control (visibility into who did the work, and the ability to keep data on the client’s platform).
As models move toward agentic behavior and tool use, the definition of good data becomes more contextual, more domain-specific, and more expensive. That increases the premium on expert networks and operational systems that can repeatedly produce high-signal artifacts. Mercor’s benchmarks also act as a standard-setting moat by shaping what progress means.
Mercor’s public roadmap points toward simulated APEX world environments: models interacting with clones of common apps (e.g., Google Workspace) via API/GUI, populated with realistic company data. This moves Mercor from expert marketplace toward economy emulator - where the training signal is an entire workflow environment.
For AI teams, the value proposition is faster evaluation → faster iteration → faster capability gain. Mercor emphasizes instruction documents as the single source of truth and argues systematic evaluation prevents teams from flying blind. For experts: high-value hourly work justified by downstream leverage - teach a model once and the learned behavior can reach billions of users.
Representative use cases:
Rubric design and eval set creation for model behavior (taste-heavy domains like writing, law, medicine).
Preference data and RLHF-style comparisons where rubrics are incomplete.
Domain-specific task and source-document creation to match real workflows (APEX’s prompt/source/rubric triplet).
Agentic evaluation in tool-rich environments (APEX-Agents; planned APEX world).
Software engineering integration/observability tasks as economically meaningful benchmarks (APEX-SWE).
The Moment the Labor Market Met LLMs
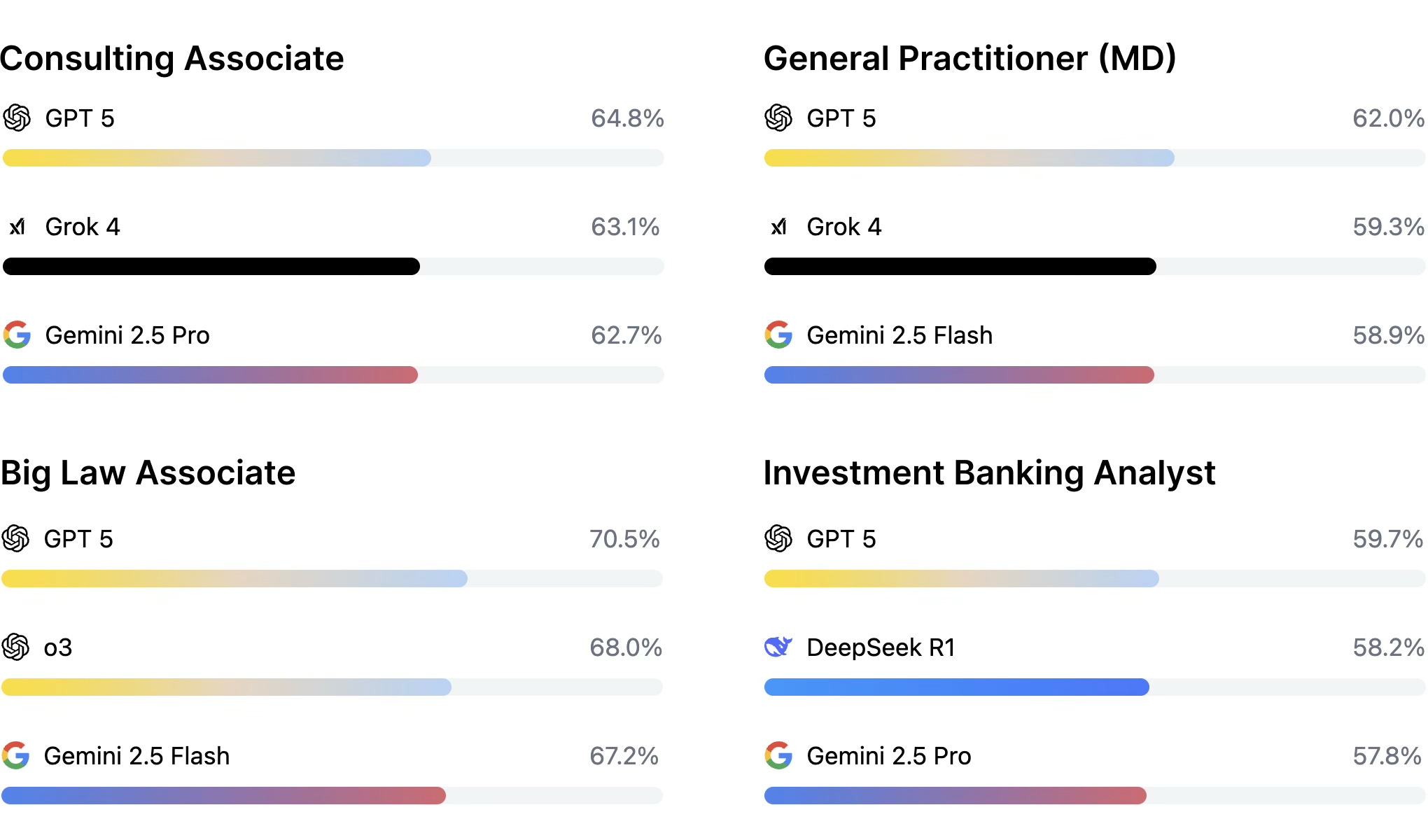
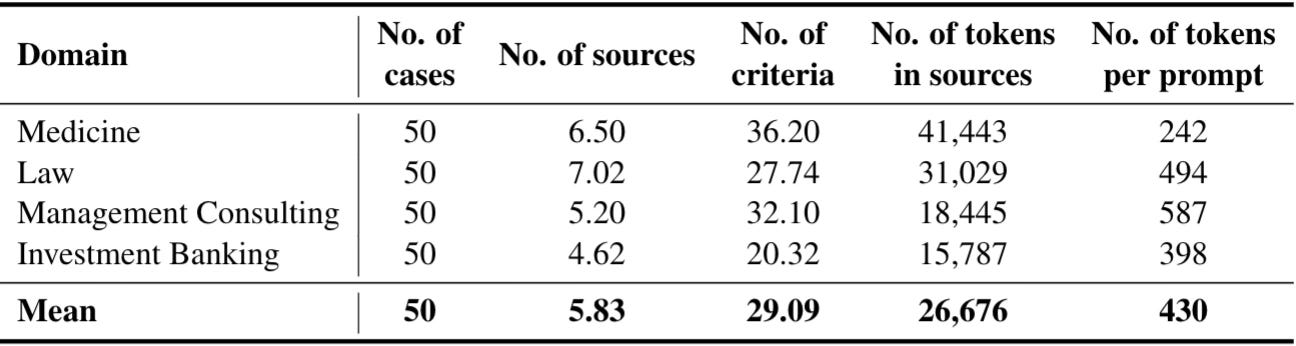
Mercor’s timing matches a shift in what AI teams need from humans: expert judgment, safety evaluation, and workflow-realistic tasks. APEX is explicitly motivated by the gap between standard benchmarks and what professionals do in the real world.
Two prerequisites were weaker historically: (1) demand at scale from AI builders willing to pay for elite labor, and (2) a consensus that talent quality - not just QA processes - is the biggest lever for frontier data quality. Mercor argues data has become core product/IP, making open box control and transparency more valuable than before.
Mercor frames the past as a fork: black-box outsourcing (vendor-run platforms) versus internal teams. Open Box recombines the two: keep the control of in-house while outsourcing sourcing, vetting, and operations.
Key enabling trends:
Enterprise AI adoption and investment increases budgets for evaluation/data workflows.
The rise of agentic systems pushes evaluation beyond static Q&A into tool-rich, long-horizon tasks (APEX-Agents).
Heightened concern over data leakage and IP control increases the relative cost of opaque vendors.
Mature global contractor rails make hourly + take rate marketplaces operationally feasible at high throughput.
How Big Is the Market for Judgment?
Mercor’s primary buyers are frontier model labs and enterprise AI groups that require expert-level human signal for training and evaluation. APEX attempts to invent a measurement category: a public AI Productivity Index for economically valuable knowledge work. Indices become markets when they steer budgeting and procurement (improve APEX → buy data/evals that move APEX). Mercor frames APEX as bridging benchmarks and real professional workflows.
The working persona is typically a research/engineering lead responsible for model quality and iteration speed. They care about: tight eval loops, controlled access to sensitive data, and explainable cost/quality drivers. Mercor’s instruction-document and evaluation playbooks are written for this persona.
Everyone’s a Competitor Until You Compound
Mercor’s competitors are the managed data vendors and AI-specialized expert-talent platforms competing for the same human data + evaluation budget. Indirect alternatives arein-house human-data teams, generalist staffing firms, and consulting firms that can spin up bespoke evaluation teams.
Mercor’s plan to win is the Open Box value proposition: faster iteration than internal teams and more control than vendors. Mechanically: hourly pricing, flat-percentage take rate, transparent expert profiles, and the ability to swap talent within hours-to-days.
Competitor set:
Managed labeling / data vendors: Scale AI, Appen, TELUS International AI Data Solutions, Sama, iMerit, Surge AI.
AI-talent / expert labor platforms: Turing, Invisible, Outlier, Upwork Enterprise (generalist).
DIY alternative: in-house data operations teams.
Mercor’s clearest durable advantages:
Talent quality as the biggest lever on frontier data quality.
Iteration speed via hourly pricing and rapid restaffing.
Transparency and data control (know who handles data; optionally keep work on client platform).
Benchmark + marketplace flywheel: APEX publications build credibility and create a public scoreboard that pulls demand.
Scale signals from stated payout volume.
The Machine Behind the Marketplace
Mercor is best understood as three coupled layers:
Marketplace + identity layer.
Candidate-facing application, vetting, and matching.
Workforce operations: onboarding, payment, performance, churn management (implied by rapid restaffing).
Human Data Open Box workflow layer.
Playbooks for instructions, examples, rubrics, peer review, and QA metrics.
Pricing model: hourly + flat-percentage take rate on expert pay.
Research + benchmark layer (APEX).
Benchmarks constructed from expert workflows and graded against rubrics (APEX, APEX-Agents, APEX-SWE).
Open research artifacts: Mercor publishes papers and, for some benchmarks, links to datasets/infrastructure (e.g., APEX-Agents dataset and Archipelago”evaluation infra.
Mercor’s public roadmap is clearest through its APEX publications:
APEX world: simulated environments with clones of common applications and many more tools/files, to bridge sim2real gaps.
Expand coverage to more professions, task types, and geographies.
Continue refining human-data methodology (instructions, rubrics, QA) and incentives as scale increases.
The Series C announcement signals continued scaling of the expert network and operations.
The Flywheel: Money → Data → More Money
Mercor aims to be a critical part of the AI training/evaluation supply chain: the default place teams go for trusted expert judgment at speed. The economic structure resembles a marketplace: take rate on gross payouts, potentially augmented by tooling and enterprise support (not explicitly disclosed).
Mercor states that after initial scoping, it “takes a flat percentage of the annotators’ pay rates.” This implies a GMV-based take-rate business, with revenue scaling alongside expert payout volume.
Mercor positions pricing as simple hourly pricing rather than per-task renegotiation. Specific take-rate percentages and enterprise rate cards are not publicly disclosed.
The Labor Market, Rewritten
Mercor’s trajectory implies a shift from expert marketplace to human-judgment infrastructure for AI:
A default operating system for expert data.
Teams run continuous evaluation and data-generation loops (instructions → rubrics → metrics → iteration) using Mercor’s playbooks and expert network.
Public standards for what models should do at work.
APEX becomes a widely referenced benchmark family, expanding roles and adding tool-use worlds.
Economy simulation as a training primitive.
APEX world becomes a source of next-generation RL environments where models learn workflows.
A network effect that is hard to unwind.
Higher pay attracts better experts; better experts create better signal; better signal attracts more demand.
Mercor’s master plan suggests ambition beyond staffing toward a structural shift in how human knowledge becomes machine capability.
Sources
Mercor Blog - Unlocking Human Potential in the AI Economy (Series C announcement). https://www.mercor.com/blog/unlocking-human-potential-in-the-ai-economy/
Mercor Blog - Mercor’s Secret Master Plan. https://www.mercor.com/blog/mercors-secret-master-plan/
Mercor Blog - Big things. https://www.mercor.com/blog/big-things/ (Accessed Feb 2, 2026).
Mercor Blog - Introducing APEX: The AI Productivity Index (Oct 1, 2025). https://www.mercor.com/blog/introducing-apex-ai-productivity-index/
Mercor Blog - Introducing Mercor. https://www.mercor.com/blog/introducing-mercor/
Mercor Human Data Handbook - Black Box vs. Open Box. https://humandata.mercor.com/mercors-approach/black-box-vs-open-box
Mercor Human Data Handbook - Creating Clear Project Instructions for Your Experts. https://humandata.mercor.com/how-to/write-great-instructions
Vidgen et al. (Mercor). The AI Productivity Index (APEX) (arXiv:2509.25721). https://arxiv.org/abs/2509.25721
Vidgen et al. (Mercor). APEX-Agents (arXiv:2601.14242). https://arxiv.org/abs/2601.14242
Kottamasu et al. (Mercor). APEX-SWE (arXiv:2601.08806). https://arxiv.org/abs/2601.08806
Mercor - APEX Benchmarks (leaderboard). https://www.mercor.com/apex
Mercor - Careers. https://www.mercor.com/careers
Tyler Cowen (Marginal Revolution). My excellent Conversation with Brendan Foody (excerpt + transcript link). https://marginalrevolution.com/marginalrevolution/2026/01/my-excellent-conversation-with-brendan-foody.html
GlobeNewswire. AI Training Dataset Market Size & Share Report (mentions 2025 value and forecast). https://www.globenewswire.com/news-release/2025/07/17/3116264/28124/en/AI-Training-Dataset-Market-Size-to-Worth-USD-26-92-Billion-by-2034-Driven-by-Rapid-Adoption-of-Generative-AI-and-AI-Driven-Automation-Research-by-Transparency-Market-Resear.html
MarketsandMarkets / ResearchandMarkets release. Data Annotation and Labeling Market report (mentions 2025 size). https://www.prnewswire.com/news-releases/data-annotation-and-labeling-market-worth-7-01-billion-by-2029---exclusive-report-by-marketsandmarkets-302405129.html
Mordor Intelligence. Data Annotation Tools Market report (mentions 2025 size). https://www.mordorintelligence.com/industry-reports/data-annotation-tools-market
Stanford HAI. AI Index Report 2025 (adoption and investment context). https://hai.stanford.edu/ai-index/ai-index-report-2025
Mercor Human Data Handbook - Incentive Structures. https://humandata.mercor.com/mercors-approach/incentive-structures
Mercor Human Data Handbook - A Guide to Evaluating and Improving Your LLM. https://humandata.mercor.com/how-to/design-a-data-pipeline
Mercor Blog - APEX-Agents (Jan 15, 2026). https://www.mercor.com/blog/apex-agents/
Mercor (official LinkedIn company page). https://www.linkedin.com/company/mercor-ai
Brendan Foody (CEO) on X: Series C announcement thread (mentions daily payouts).


Mercor (official LinkedIn post): ‘Behind every breakthrough in AI is human...’ (mentions payouts and rates). https://www.linkedin.com/posts/mercor-ai_behind-every-breakthrough-in-ai-is-human-activity-7373790733134315520-e_v-
Mercor (official X) on APEX: post linking benchmark design.

Mercor (official X): post about APEX-Agents dataset and Archipelago.


Didn't expect this take on the critical role of expert human judgment in AI; do you think Mercor's model risks centralizing even more power within this new 'expert' class, or does it truly help democratize access to high-quality training data for everyone? You've really articulated Mercor's value proposition and the systemic problems it addressses so clearly, it makes perfect sense now.