
LangChain and the Rise of Agent Engineering
Shipping agents is becoming its own software category.

LangChain provides the agent engineering platform and open-source frameworks developers need to ship reliable AI agents fast. LangChain spans three layers that are often owned by different groups: (1) the open-source developer framework layer, (2) the control-plane layer for debugging and evaluation, and (3) the production runtime + deployment layer. It can look like a library, a platform, or a methodology, depending on where you stand. LangChain is a familiar enterprise-software pattern wearing unfamiliar clothes: an open-source distribution engine feeding a paid control plane, where recurring usage-based spend compounds as customers run more production workloads.
Why LLM Apps Fail in the Real World
The customer pain is a three-part failure mode:
Debugging is opaque: when an agent does something wrong, the “why” is buried in a shifting context window (tool calls, retrieved docs, intermediate reasoning).
Testing is underspecified: you cannot exhaustively enumerate “inputs,” and small prompt/config changes can cause large behavioral shifts.
Deployment is alien: long-running, stateful, bursty agents break common serverless assumptions (timeouts, retries, background jobs, human-in-the-loop pauses).
Before LangChain, teams stitched together a patchwork: a framework (or bespoke glue code), generic observability (logs/APM), a spreadsheet of prompts and test cases, and a deployment stack designed for stateless APIs. That approach fails for agents for a reason LangChain keeps repeating: the primary artifact is the run, not the code. In Sequoia’s 2026 interview, Harrison Chase frames traces as the new source of truth because you cannot know what the context at step 14 will be without seeing steps 1–13.
Generic observability tools can tell you latency, errors, and maybe token counts; they do not give you first-class representations of agent trajectories, tool calls, and the exact context that drove a decision. Generic testing tools assume determinism; offline golden tests degrade under distribution shift; and deployment platforms assume your request finishes before the load balancer loses patience. LangChain’s lays out why long-running/stateful agents need purpose-built infrastructure (checkpointing, rejoinable streams, task queues, TTL’d memory).
From Building Blocks to a Platform for Shipping Agents
LangChain’s founding insight: large language models are rarely the product. They are the reasoning engine inside a larger system. The system becomes much more valuable when the model can reach into external data and act on APIs, what LangChain calls agents. That, in turn, creates a new class of engineering problems: non-deterministic behavior, shifting context, and long-running workflows.
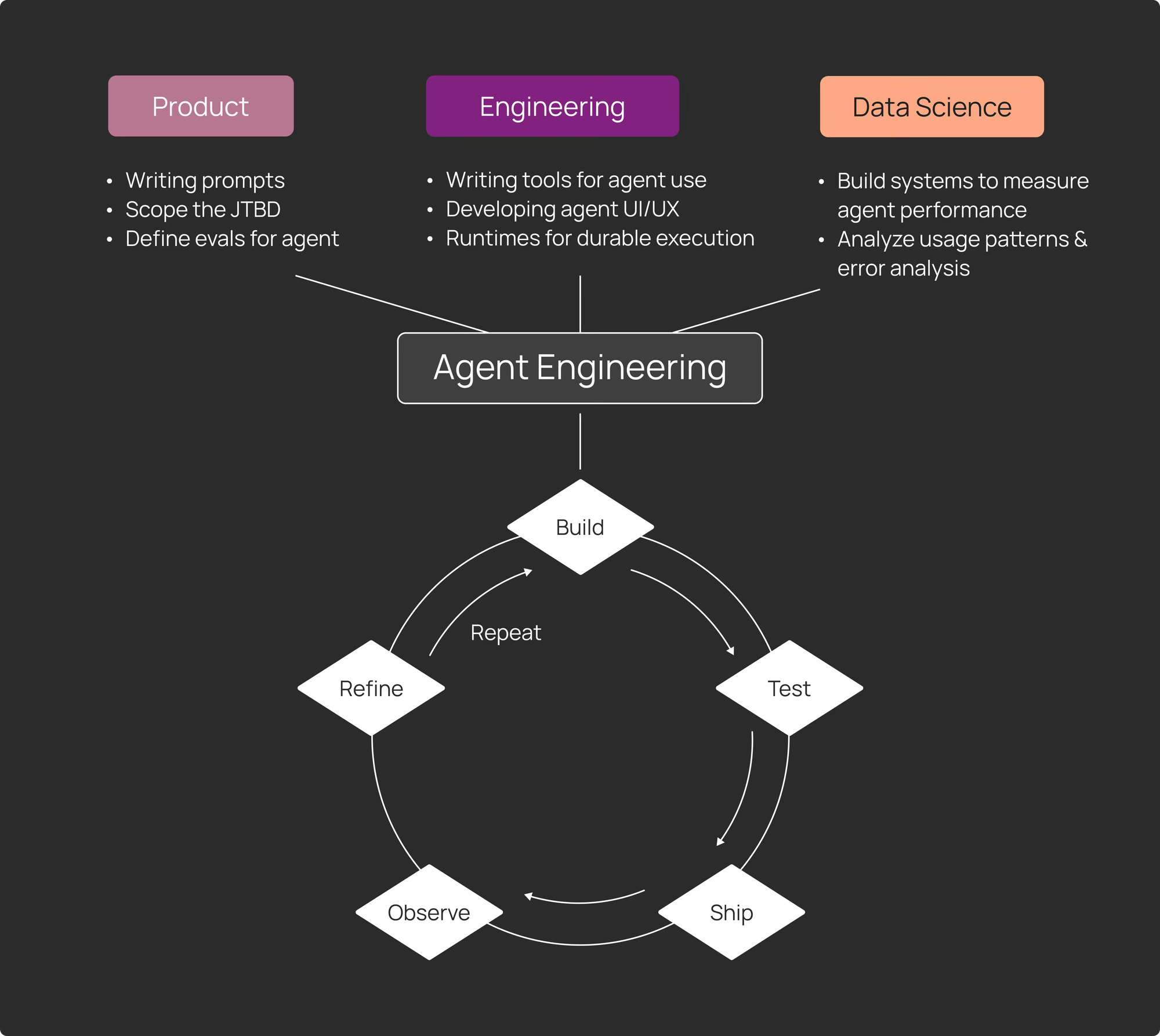
LangChain is a lifecycle stack more than a framework. The unique value proposition is the glue between stages that are normally fragmented across tools and teams:
Build: LangChain (fast start) + LangGraph (controllable runtime)
Observe and test: LangSmith (tracing + evals) designed to work even if you use a different framework
Deploy: LangSmith Deployment (formerly LangGraph Platform) designed for long-running/stateful agents, and REST endpoints
Lower the barrier: Agent Builder (no-code) and automated Insights for behavior patterning
This integration creates compounding returns for the customer: once the traces, datasets, and eval harnesses exist, every additional iteration becomes cheaper and safer.
Durability here is about a persistent need: agent reliability. As soon as agents leave the lab, teams need: (1) visibility into what happened, (2) a way to measure quality and regressions, and (3) an operating model for iterating. LangChain is trying to make agent engineering the default playbook. LangChain is betting that agents become a core software primitive, and that their reliability tooling becomes as non-negotiable as CI/CD and production monitoring.
A typical workflow (and the promise) looks like this:
Instrument everything: enable tracing by default during development; treat every failure report as a request for a trace.
Turn production into labeled data: promote interesting traces into datasets, attach human feedback, and run evals on changes before shipping.
Close the loop with deployment: deploy the agent to infrastructure that supports long-running background runs, streaming, retries, and checkpointing.
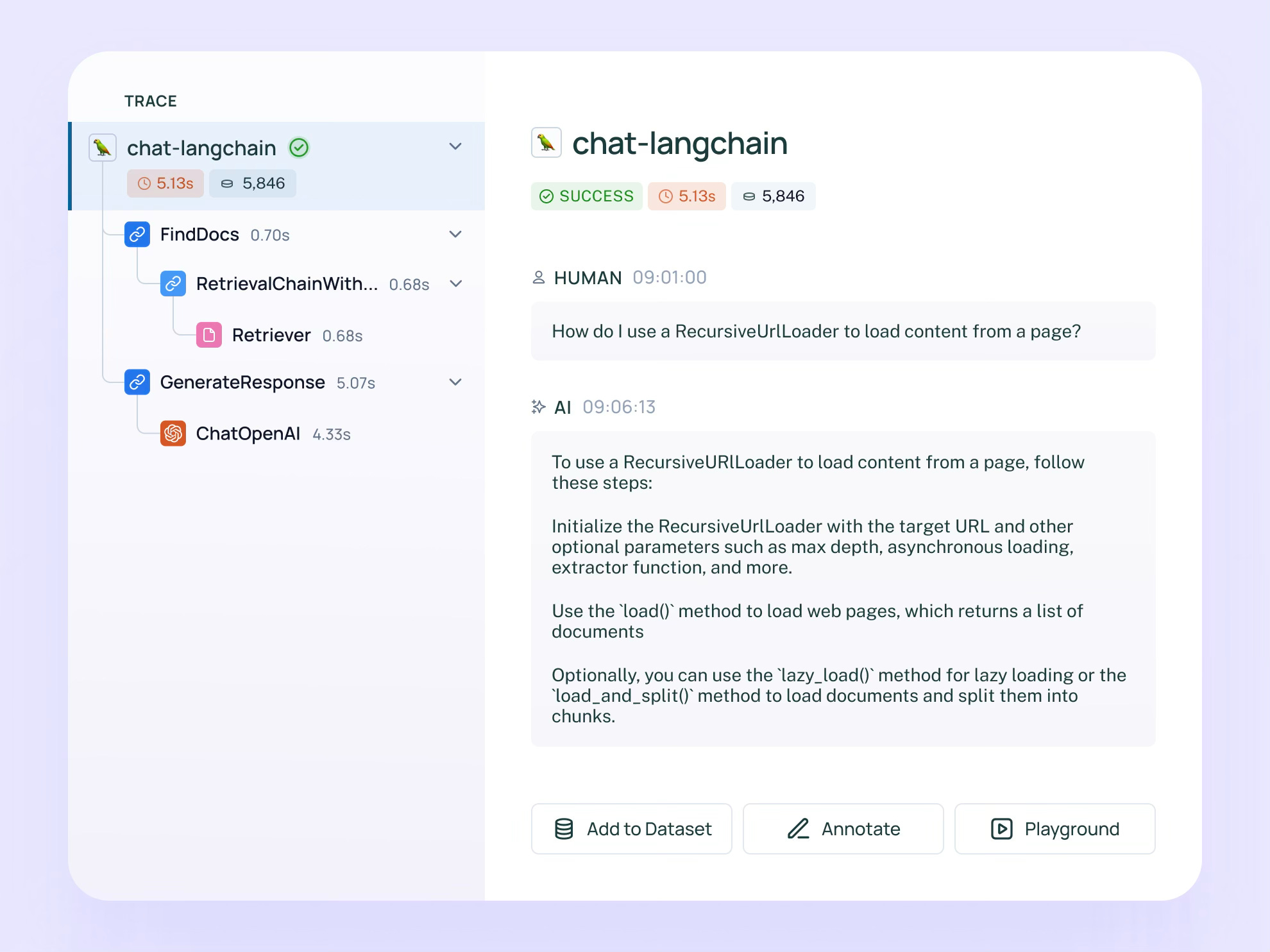
LangChain’s stack sits between model providers and application teams, bridging the gap between experimentation and production.
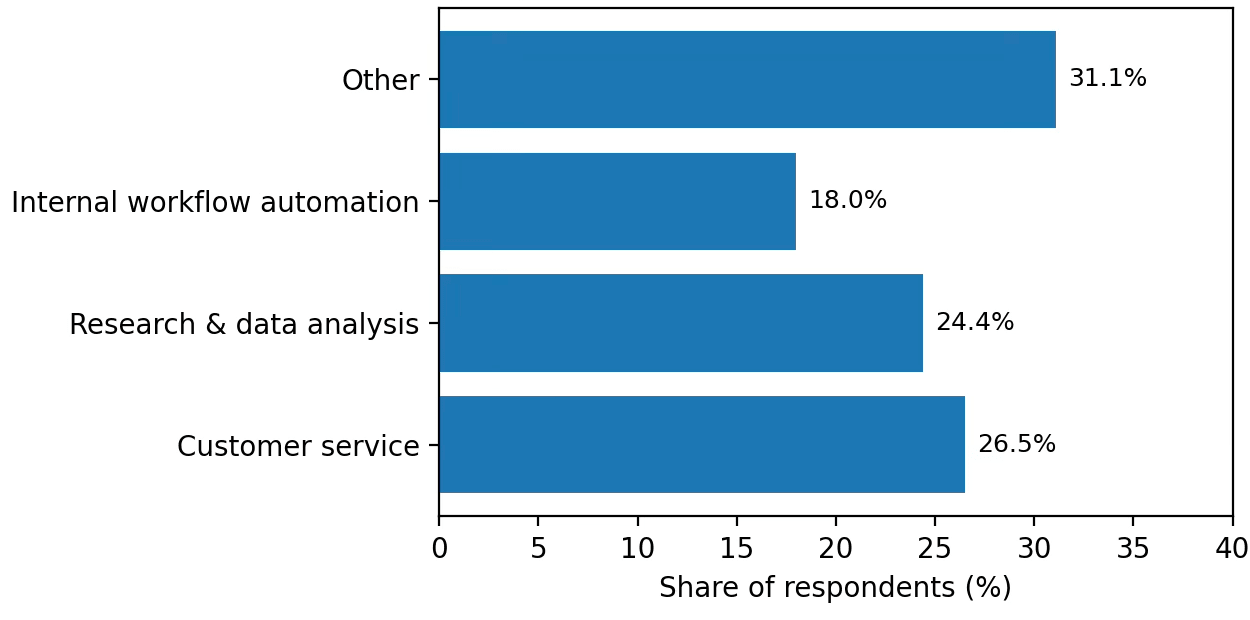
LangChain makes clear where agents are most valuable today: customer service and research/data analysis lead, with internal workflow automation close behind.
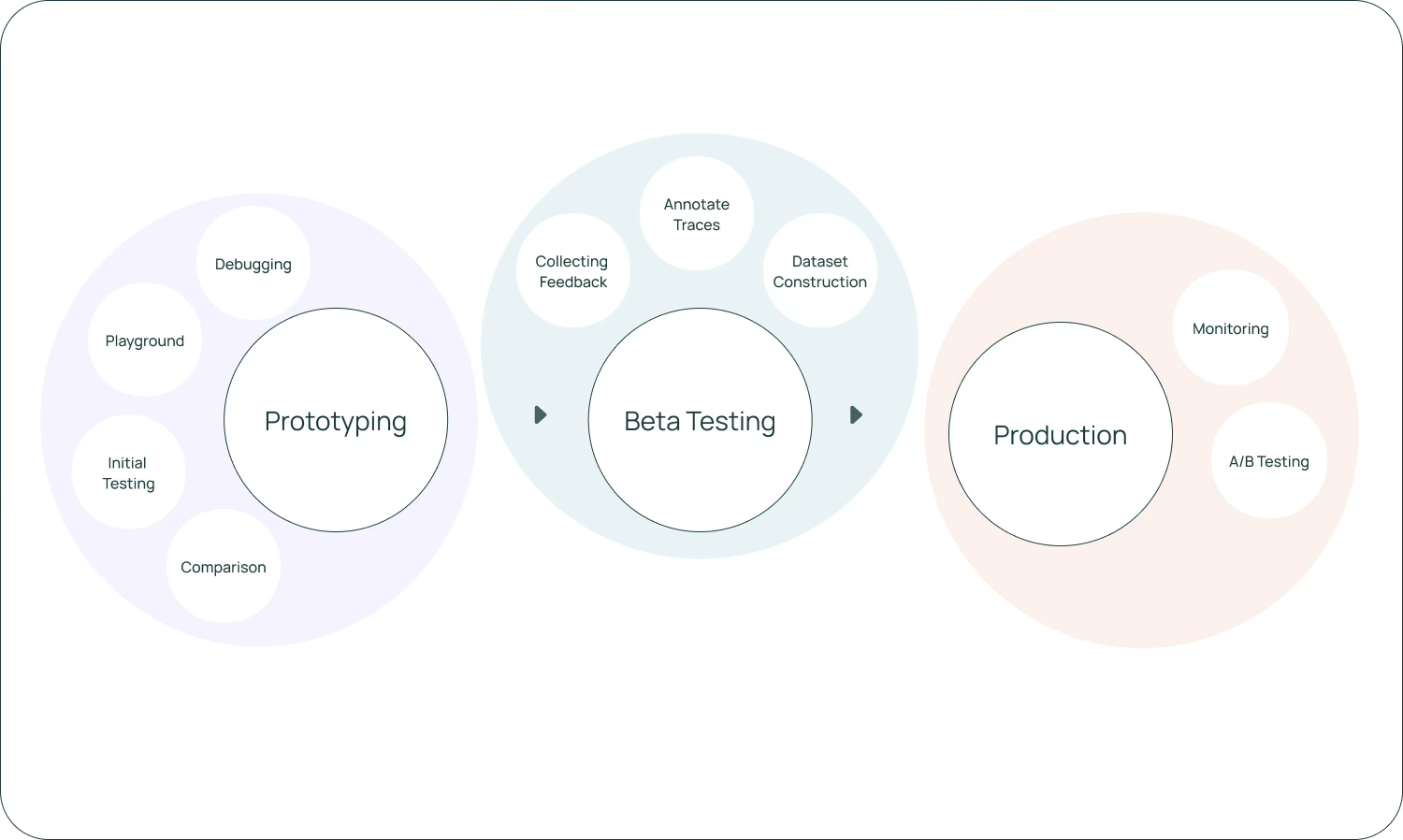
Examples:
Enterprise agent deployment and management (e.g., LangGraph Platform used by nearly 400 companies in its beta-to-GA period).
Customer support copilots and escalations (Klarna and customer support as a canonical long-horizon use case).
Research and first draft generation workflows (coding agents, AI SREs, report generation).
Why This Category Couldn’t Exist Until Recently
Workload changed. As soon as agents take on multi-step work (and touch production systems), reliability becomes the bottleneck more than model access. Two things had to become true simultaneously: (1) agents needed to be capable enough to justify serious production investment, and (2) they needed to be unreliable enough that teams demanded a new toolbox. Harrison Chase is blunt on this: early agent demos (AutoGPT) worked as a concept, but “the models weren’t really good enough, and the scaffolding and harnesses around them weren’t really good enough.”
LangChain’s historical evolution
Late 2022: LangChain starts as an open-source side project; a month later ChatGPT launches and usage accelerates.
2023: The first wave of agents (LLM-in-a-loop) captures imagination; LangChain raises seed funding to build more production tooling.
2023–2024: LangSmith beta (observability + evals) appears as teams hit quality problems; LangGraph emerges to answer demand for control and a production runtime.
2025: Deployment becomes the next bottleneck; LangGraph Platform (later LangSmith Deployment) reaches GA; by Oct 2025, LangChain announces 1.0 releases and positions itself as a full platform.
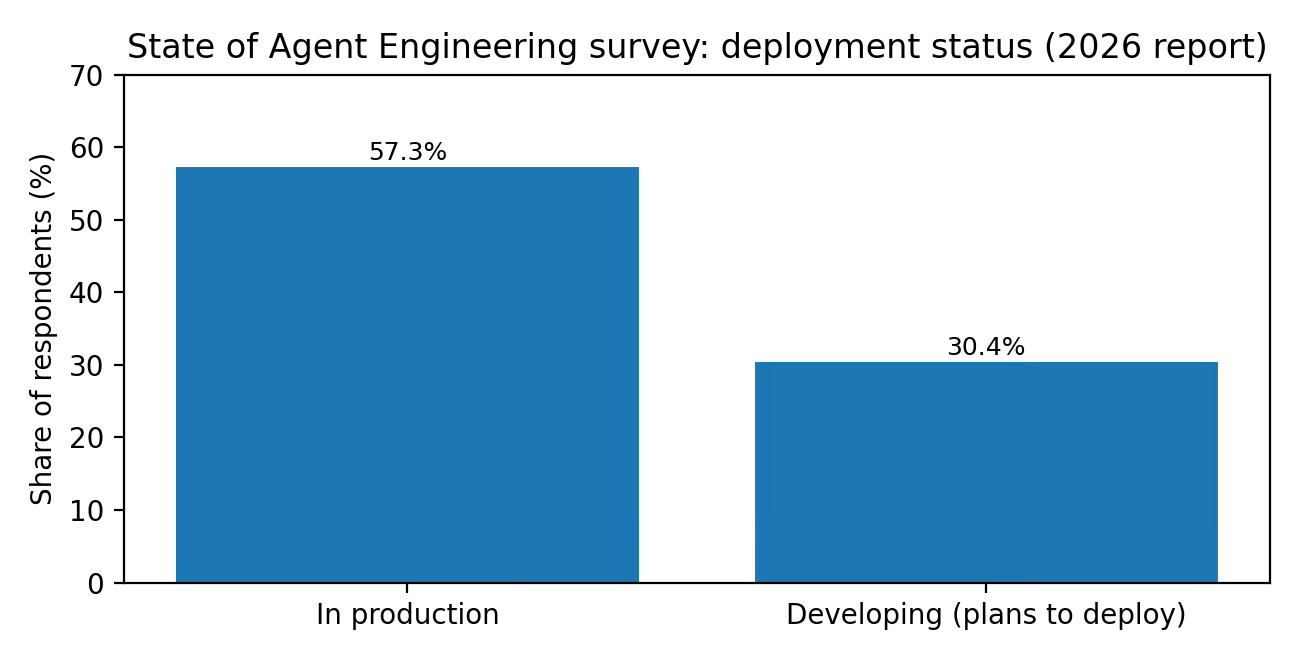
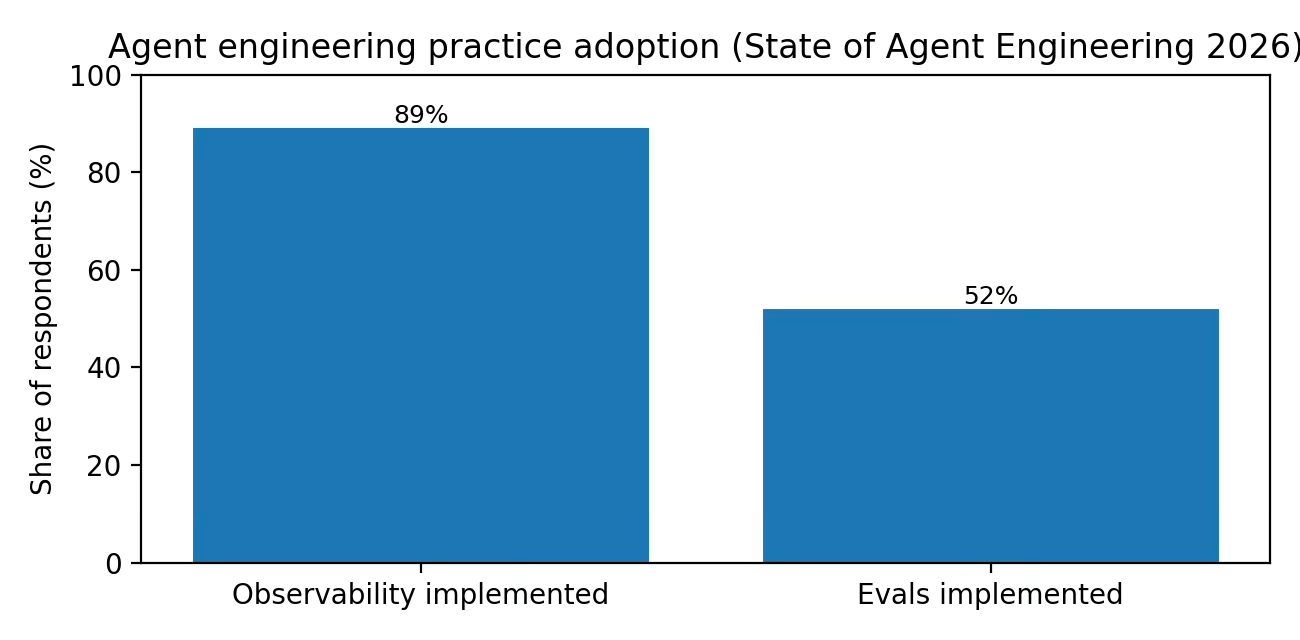
2026: The discipline hardens. LangChain’s survey reports majority production usage and near-universal observability adoption among teams building agents.
Several trends pull in the same direction:
Longer-horizon model performance: models can now sustain multi-step work without collapsing into nonsense, especially in code and research.
Harness engineering: planning tools, compaction strategies, file-system interfaces, and durable runtimes, engineering patterns that did not exist in 2022, now matter as much as model choice.
A cultural shift: teams are learning that shipping is how you learn, and production traces are the raw material for improvement.
The Market LangChain Is Trying to Name
LangChain sells to the people who are embarrassed when an AI agent makes a mess: engineers, PMs, and platform teams who must make non-deterministic systems dependable. In practice, the customer ladder looks like:
Solo developers and small teams (free Developer plan, self-serve).
Product teams shipping early production agents (Plus plan, self-serve collaboration + a managed dev deployment).
Enterprises with security, hosting, governance, and support requirements (Enterprise plan; hybrid/self-hosted options).
The market is best described as agent engineering infrastructure: orchestration runtimes + observability + evaluation + deployment for AI agents. It overlaps with MLOps and observability, but it is narrower and more specialized. LangChain is actively attempting to name and standardize the category: agent engineering. They define it as an iterative cycle, build, test, ship, observe, refine, repeat.
The clearest psychographic is the team already past the vibe check phase. They care about (a) regressions, (b) reliability, (c) auditability, and (d) iteration speed. LangChain’s own survey highlights quality as the leading barrier to production and observability as table stakes.
LangChain names a mix of AI-native startups and global enterprises as customers:
Replit, Clay, Harvey, Rippling, Cloudflare, Workday, Cisco.
Rakuten, Elastic, Moody’s, Retool.
LinkedIn, Uber, J.P. Morgan, BlackRock (as production validators for LangGraph’s control + runtime).
Clay, Vanta, LinkedIn, Cloudflare (as teams shipping reliable agents).
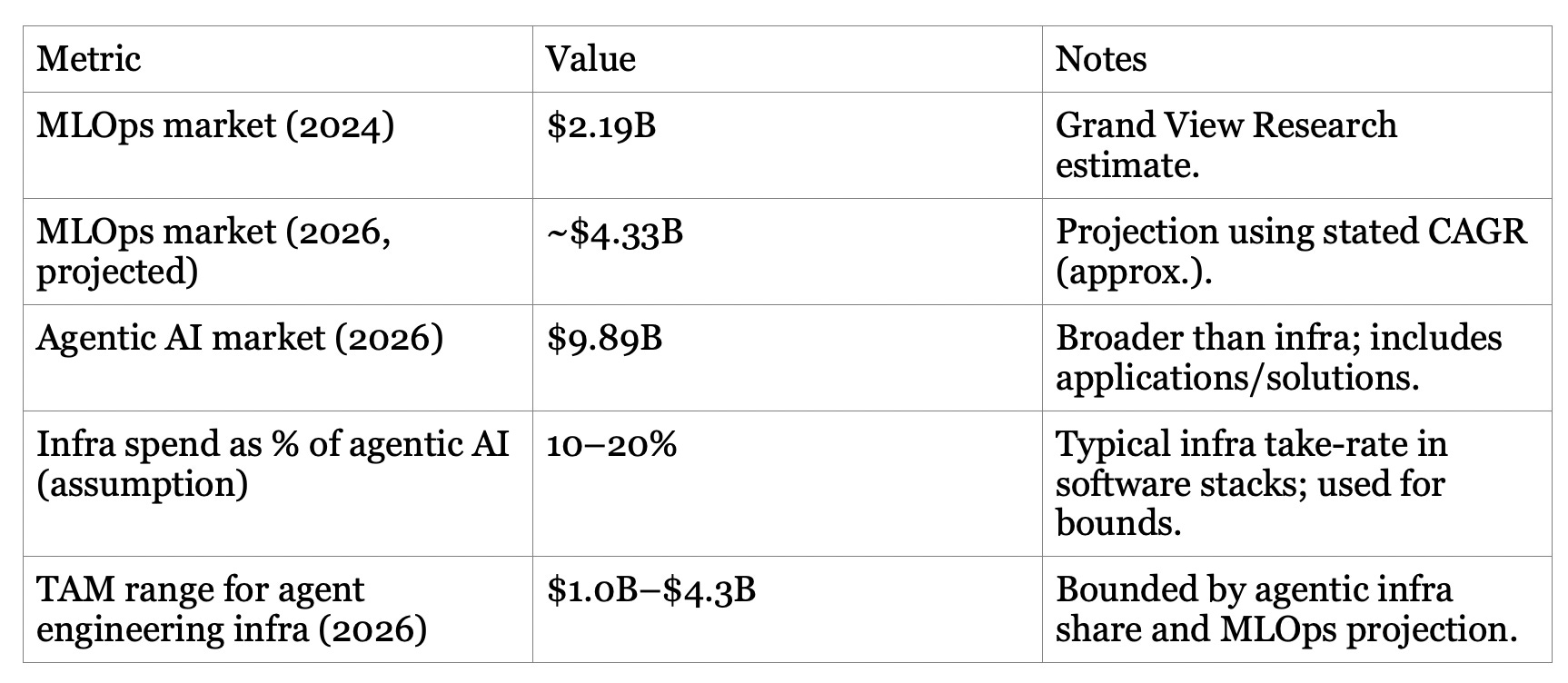
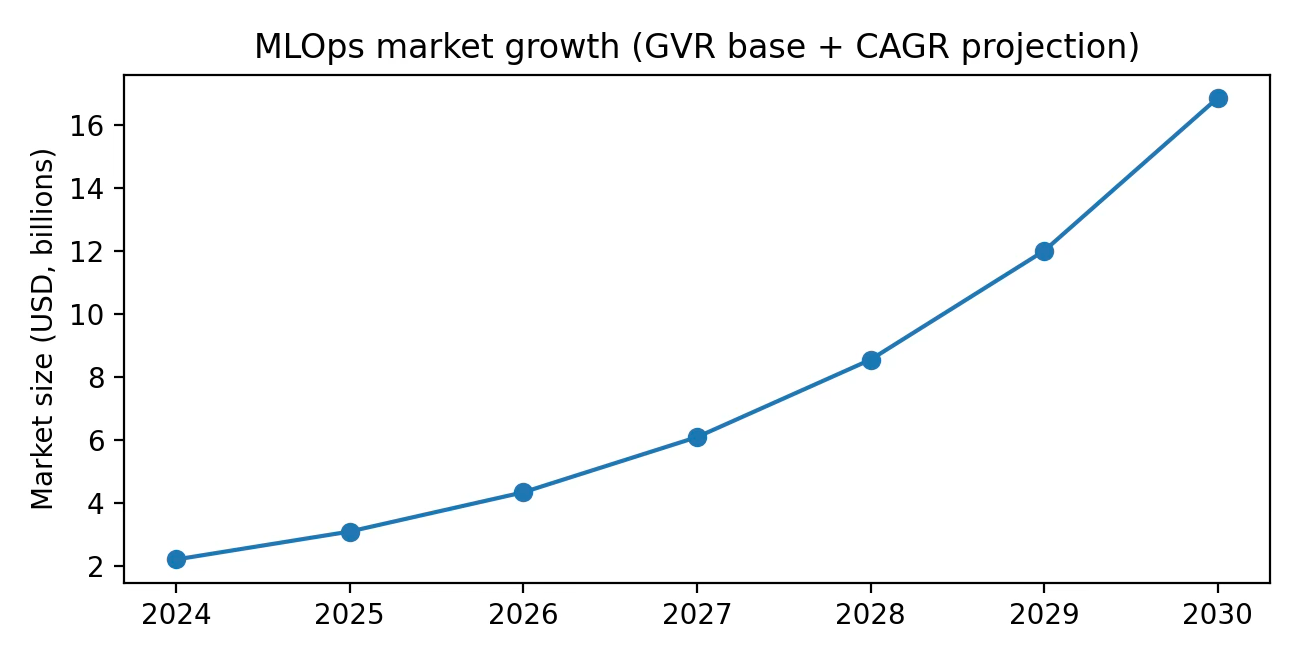
Bottom-up SAM and SOM are even more assumption-heavy. A useful anchor is the company’s own scale signals: as of early 2024 LangSmith reported 5K monthly active teams; by Oct 2025 LangChain reported 35% of the Fortune 500 uses its services. A conservative bottom-up SAM framing is: enterprises and mid-market teams actively running agents in production that require tracing, evals, and deployment. If we assume 25–40% of the broader MLOps category maps to agent engineering in 2026, SAM lands around $1.1B–$1.7B. A plausible SOM for a category leader might be 10–20% share over time; LangChain’s open-source distribution (and existing large-enterprise penetration) makes this credible, but not guaranteed.
The Orchestration Land Grab
LangChain competes in three arenas at once (framework, lifecycle tooling, deployment). That means it faces different competitors depending on where you slice the stack:
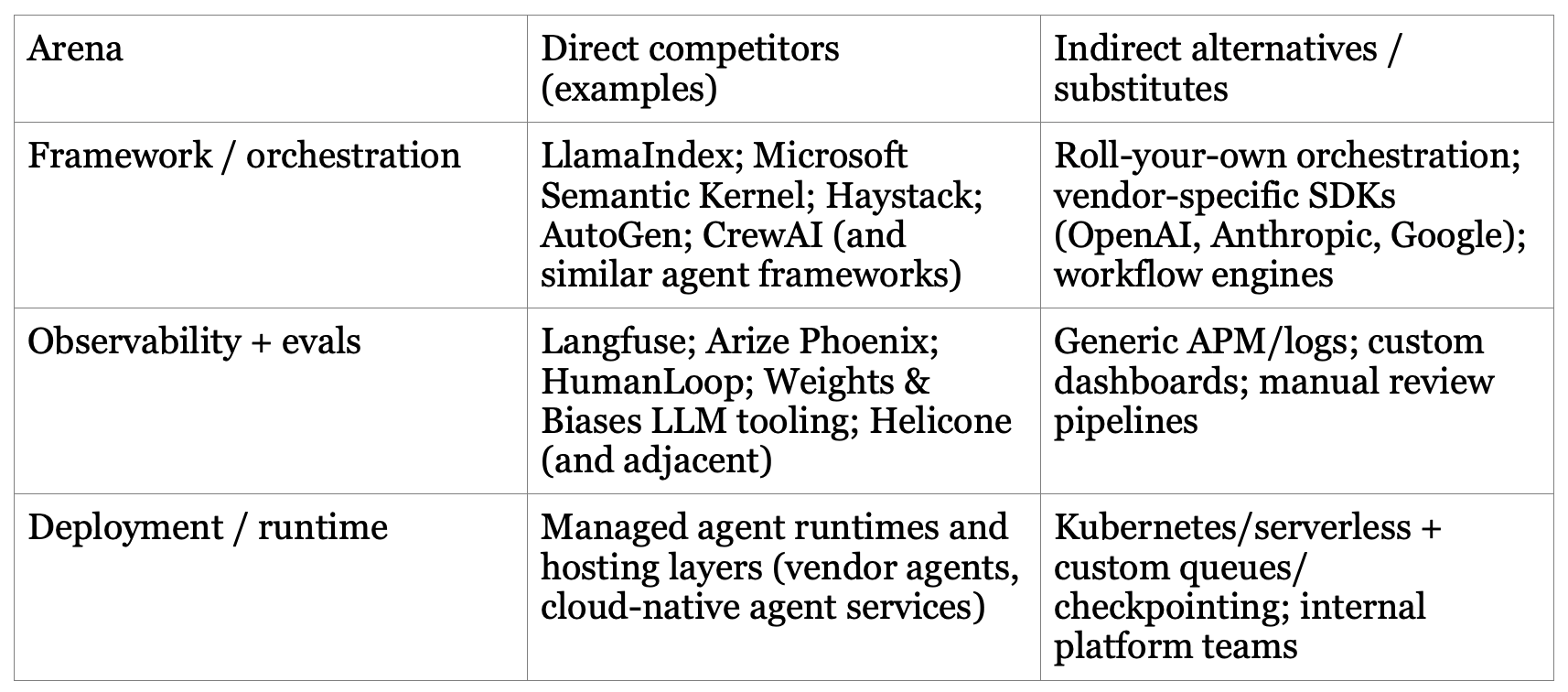
LangChain’s plan is to make reliability the center of gravity, and to own the iterative loop. The company has publicly moved from framework popularity to platform for agent engineering, bundling build + observe + evaluate + deploy. The 1.0 rewrites matter. They are an admission that early LangChain won distribution but accumulated technical debt; LangGraph (control + runtime) is the corrective, and LangSmith is the monetization vector.
Competitive advantages
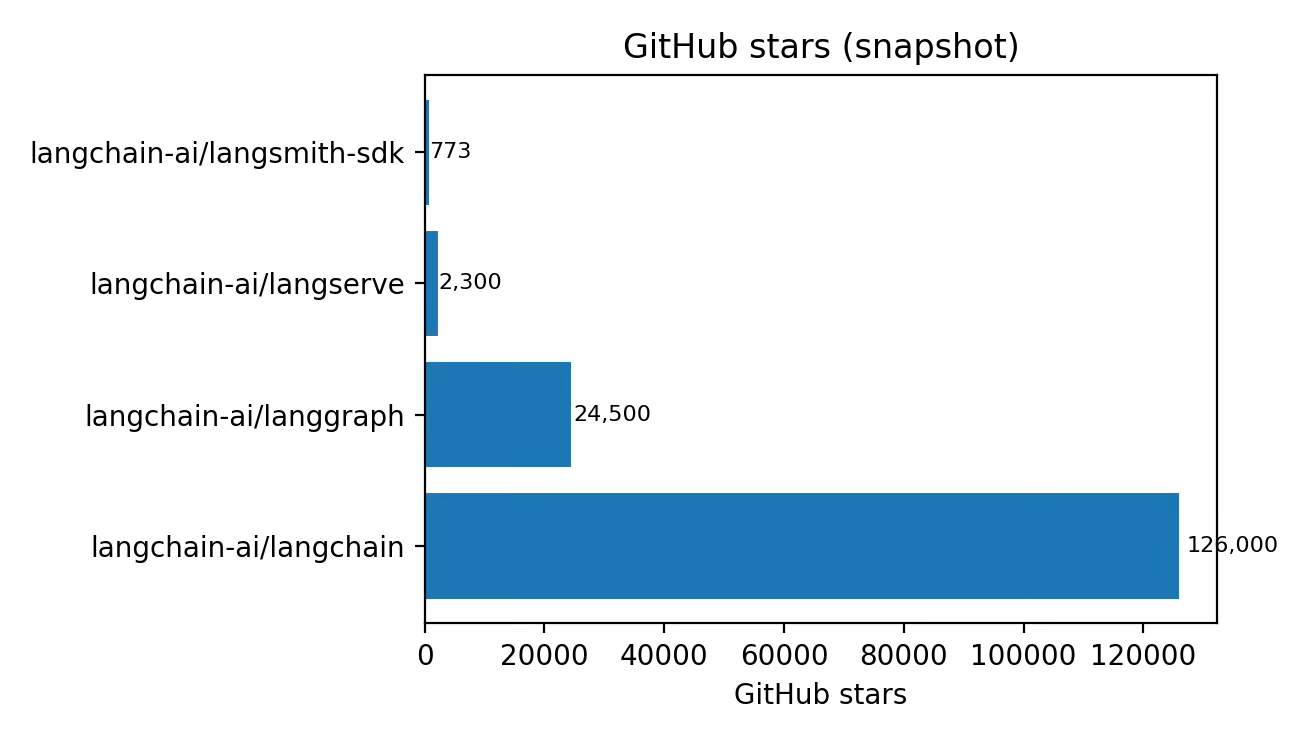
Distribution moat: massive open-source adoption (GitHub stars, downloads) funnels developer mindshare.
Model and framework neutrality: choose the best model for the job, no matter the vendor, and use LangSmith even without LangChain.
End-to-end feedback loop: traces -> datasets -> evals -> deployment, all in one stack, reduces integration friction.
Production-first runtime: LangGraph’s design emphasizes controllability (no hidden prompts/context) and durable execution/human-in-the-loop support.
Data network effects (emerging): organizations accumulate proprietary traces, feedback, and eval datasets inside the platform; switching costs rise with history.
Key competitive risks are equally clear: (1) model providers moving up the stack with first-party agent runtimes, (2) best-of-breed observability vendors out-innovating, and (3) open-source forks eroding control. LangChain’s response is to remain open and composable while integrating the agent engineering workflow tightly enough that customers prefer the bundle.
The Stack: OSS + Platform + Enterprise Surface Area
LangChain’s product surface area is best understood as two rails: open-source frameworks for building, and a commercial control plane for operating.
Open-source frameworks (distribution + developer experience)
LangChain (Python/JS): quick-start patterns and integrations; 1.0 rewritten to be more opinionated and powered by LangGraph’s runtime.
LangGraph: low-level orchestration using graphs; designed for controllability, memory, human-in-the-loop, and durable execution.
LangServe: tooling to serve chains/graphs as APIs (still used, but increasingly positioned as complementary to the more agent-native deployment stack).
Commercial platform: LangSmith (monetization + reliability)
Observability: traces, monitoring, alerting, and an Insights Agent for behavior patterning.
Evaluation: offline and online evals; datasets; regression tracking; comparison views.
Deployment: managed runtime for long-running, stateful agents (LangSmith Deployment; formerly LangGraph Platform).
Agent Builder: no-code text-to-agent experience.
LangChain’s roadmap:
Stability and curation: 1.0 releases with an explicit promise of no breaking changes until 2.0.
Consolidation into LangSmith: deployments brought into LangSmith, with more product lines planned as independent modules that integrate well.
Shift from scaffolds to harnesses: more opinionated, batteries-included agent harnesses (deep agents” and better context engineering.
Enterprise readiness: RBAC, SSO, hosting options (hybrid/self-hosted) and support SLAs as core packaging for large customers.
Quality toolchain expansion: regression testing, online evaluators on production samples, and richer conversation support.
Open Source as Distribution, SaaS as Monetization
LangChain follows the modern open-source enterprise playbook: grow a large developer surface area for free, then monetize the operational layer that becomes mandatory in production.Open is part of the ethos, and LangSmith is designed to be usable even without LangChain.
Public pricing suggests a blended model: seat-based collaboration plus usage-based metering tied to the things that scale with production adoption.
Seats: Plus is listed at $39 per seat per month.
Usage (observability/evals): traces billed by retention class (base vs extended).
Usage (deployment): deployment runs and uptime minutes billed for additional deployments beyond the included dev deployment.
Usage (no-code): Agent Builder runs billed beyond included quotas.
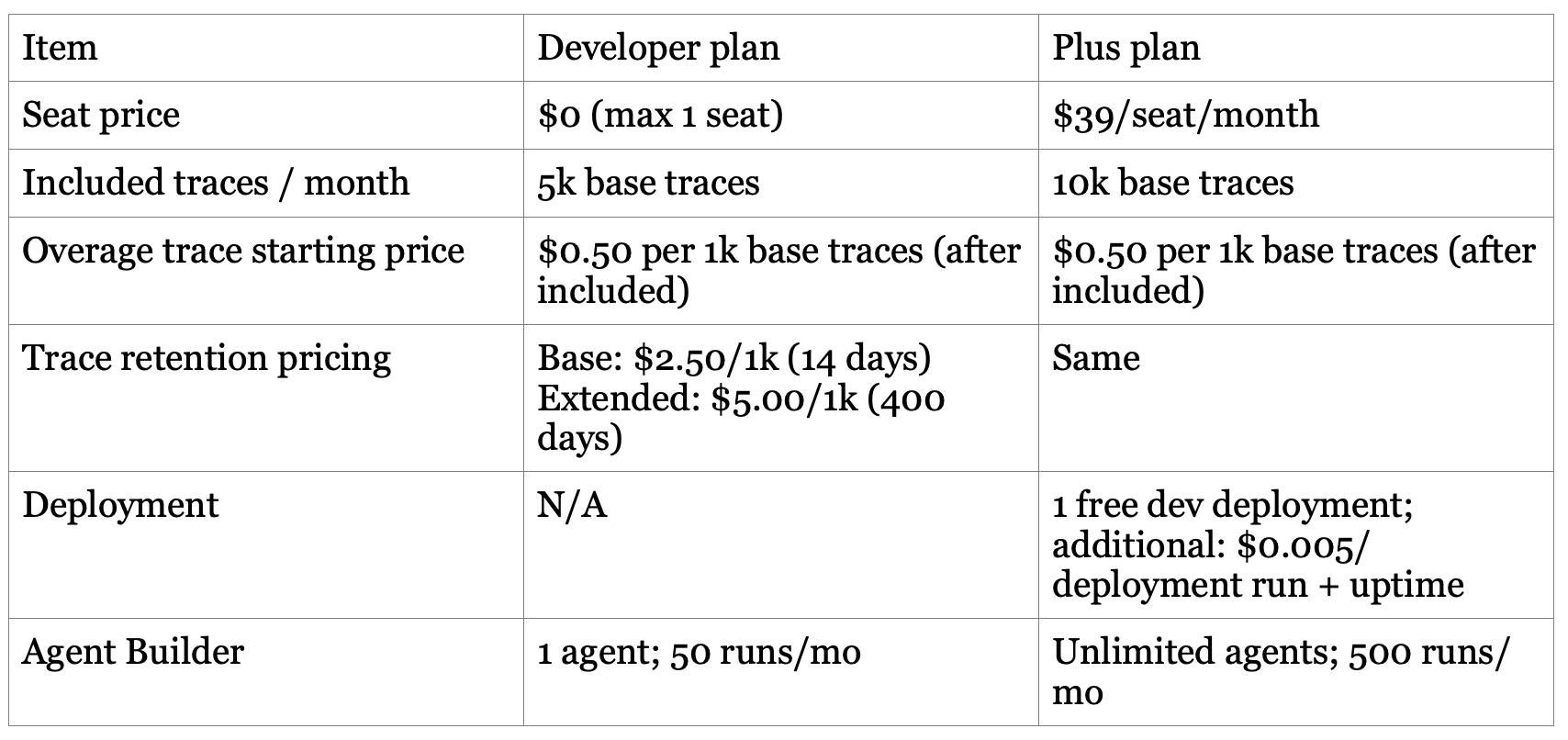
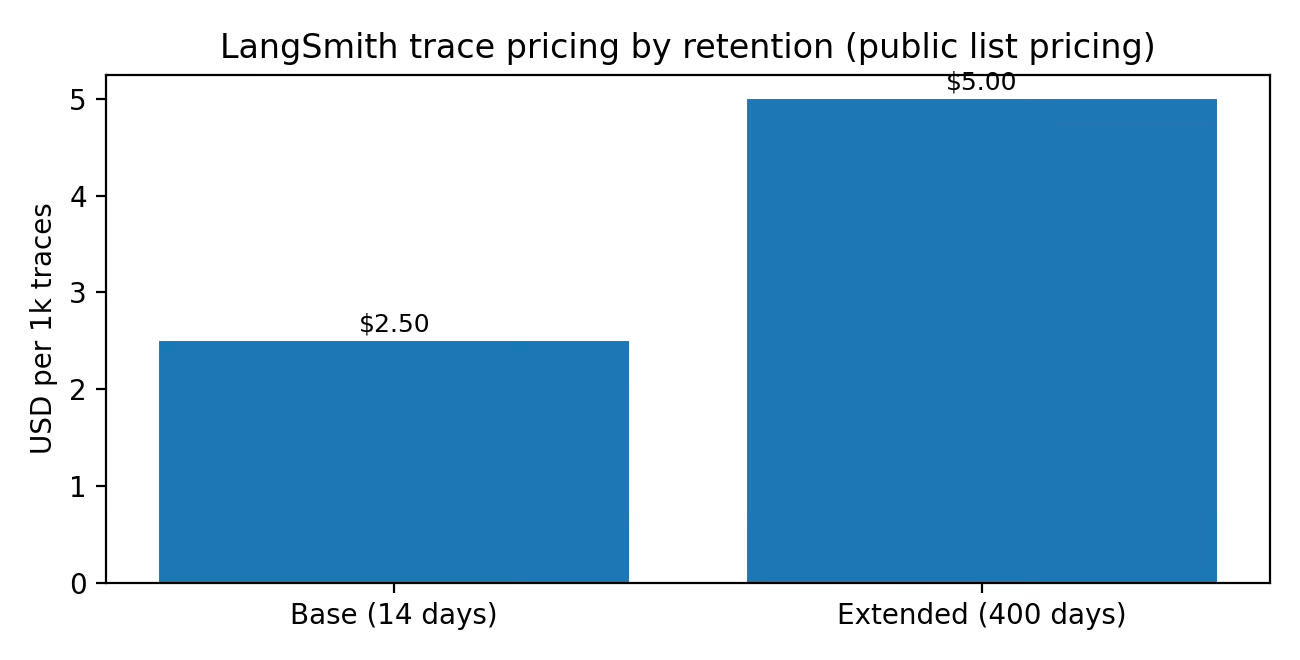
LangChain does not disclose ARPA, retention, or LTV publicly. The pricing structure, however, hints at the intended expansion path: start with a few seats and limited traces, then grow with production volume (traces, deployments, uptime). In effect, LangChain is selling a toll booth on iteration: the more you ship and observe, the more you pay, ideally because you are making or saving more.
Distribution is led by open source (downloads, GitHub stars, community), then captured via self-serve conversion and enterprise contracts. The pricing page is explicitly self-serve for Developer/Plus and Contact sales for Enterprise. A subtle point: by keeping LangSmith usable without LangChain, the company widens its top-of-funnel. It can sell observability/evals to teams using competing frameworks, then later pull the runtime/deployment layer in once switching costs and trust are established.
Enterprise conversion depends on security posture as much as product features. LangChain has made several concrete moves:
LangSmith announced SOC 2 Type II compliance (July 2024).
LangSmith is SOC 2 Type II, GDPR, and HIPAA compliant; and that BAAs are limited to Enterprise plans.
Regional hosting: EU instance and GDPR compliance; contracting remains via non‑EU legal entity.
Taken together, these position LangSmith as a serious candidate for regulated and large-enterprise workloads, precisely the segment where agent adoption creates recurring, high-volume trace and deployment usage.
Financials
Revenue drivers: seats + usage (traces, deployments, uptime minutes, agent builder runs).
COGS drivers: cloud compute/storage for trace ingestion/retention, deployment runtime compute, support, and possibly model-related pass-through (model usage billed separately by providers).
Operating expense drivers: engineering (open-source + platform), go-to-market (enterprise sales), community, and security/compliance.
Disclosed cumulative funding is $160M.
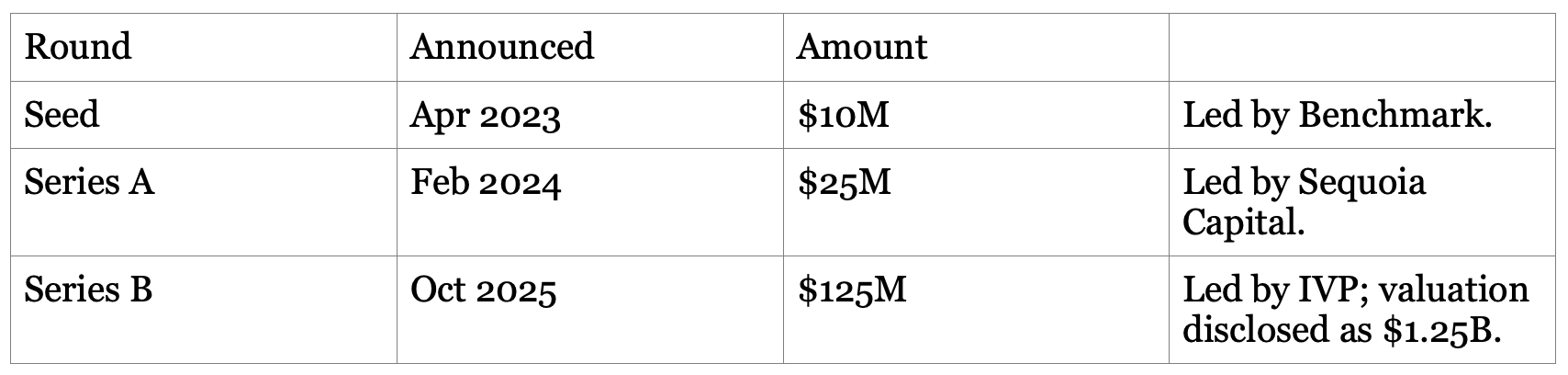
The shape of the model:
The business is likely gross-margin positive at scale (software control plane + metered usage), but early-stage burn is usually driven by R&D and go-to-market hiring.
Usage-based pricing ties cash receipts to customer success: more production runs and longer retention create both value and cost, with pricing intended to preserve margin.
Enterprise plans introduce cash-flow smoothing via annual invoicing and longer-term commitments (inferred from standard enterprise procurement patterns; their pricing page notes annual invoice for Enterprise).
If LangChain succeeds, the long-term financial game (more than selling more seats) is to become the default operating system for agent iteration, so that customer growth looks like compounding: more agents -> more runs -> more traces -> more evaluation -> more deployment. The operating leverage comes from software, but the moat comes from habit and history (the stored traces and eval sets).
If It Works: LangChain as the Default Runtime for Agentic Software
If LangChain executes, by 2031 it will look more like a reliability company, the Datadog/GitHub of agents. The platform would become the place where organizations:
Define agent behavior (prompts, policies, tool contracts) the way they define API schemas today.
Observe and audit agent actions with traces as first-class artifacts (debugging, compliance, incident response).
Continuously evaluate and regress-test agents against production-derived datasets, with human and automated judges.
Deploy long-running, stateful agents with durable execution, async management, and controlled interaction patterns (human-in-the-loop, escalations).
This aligns with LangChain’s stated mission to make agents “as reliable as databases and APIs.”
The next moat is operational memory. In the 2026 Sequoia interview, Harrison argues that as agents evolve, persistent memory and context management will be key differentiators, and that traces are the source of truth for making that memory usable.
Three failure modes are worth watching:
Platform squeeze: model providers or cloud vendors bundle agent runtimes + evals + observability tightly enough that customers accept lock-in.
Abstraction decay: if the open-source frameworks become too opinionated or too volatile, the community migrates to simpler primitives.
Trust failure: a major security/privacy incident would be uniquely damaging because LangSmith handles sensitive traces and context.
The optimistic counter is that LangChain has leaned into openness and model neutrality precisely to avoid being trapped by a single vendor’s gravity.
Other notes
A useful question for LangChain is whether it becomes a true ecosystem business: a product that strengthens as usage rises (increasing returns), or a commoditized integration layer. The ecosystem are the artifacts: traces, eval datasets, deployments, and organizational know-how. If those artifacts become deeply embedded in engineering workflows, switching costs rise and network effects can show up inside the enterprise: more teams adopt the standard tool because other teams already did.
Inverting LangChain’s story surfaces a simple risk: what if agents never become reliable enough to justify heavy tooling? LangChain’s own survey and product direction suggest the opposite: agents are shipping, and the bottleneck is quality and observability rather than cost.
Outsider CEOs obsess over capital allocation and warn that strategic is often code for low returns. LangChain’s public product choices (LangSmith separate from LangChain; model neutrality; investing heavily in a controllable runtime) look like a version of this discipline: allocate engineering effort to the bottlenecks that unlock adoption (quality, controllability, deployment), not to superficial feature sprawl.