
Delineate (YC W25) Deep Dive: Agentic AI for Clinical Trial Design
Building agentic systems that turn research literature into trial-ready datasets and models.

Delineate builds domain-specific AI agents that convert messy biomedical evidence into structured datasets and models, so pharma and biotech can design better clinical trials faster. Delineate’s purpose is epistemic: to make “what do we actually know?” cheap enough to ask repeatedly, and reliable enough to bet a trial on. The company frames this as evidence-driven decision-making that de-risks development across departments.
Problem: the evidence bottleneck
Clinical development teams live in a cruel triangle: (1) decisions are expensive and irreversible, (2) the relevant evidence is fragmented and unstructured, and (3) time is monetized. The result is a recurring tax: highly trained scientists spend disproportionate time doing evidence plumbing: searching, screening, and manually extracting numbers locked inside PDFs and plots, before they can even start modeling.
Meanwhile, bad trial design (wrong dose, wrong population, wrong endpoints, wrong comparator) is cited as a leading driver of failure, and failure is common. FDA notes that over 90% of drugs that appear safe and effective in animal studies do not go on to receive FDA approval.
The financial shape of this pain is unintuitive. A Tufts CSDD analysis estimates a day of delayed sales at about $800,000 on average, while estimating mean direct clinical trial costs per day around $40,000 for Phase II and III trials.
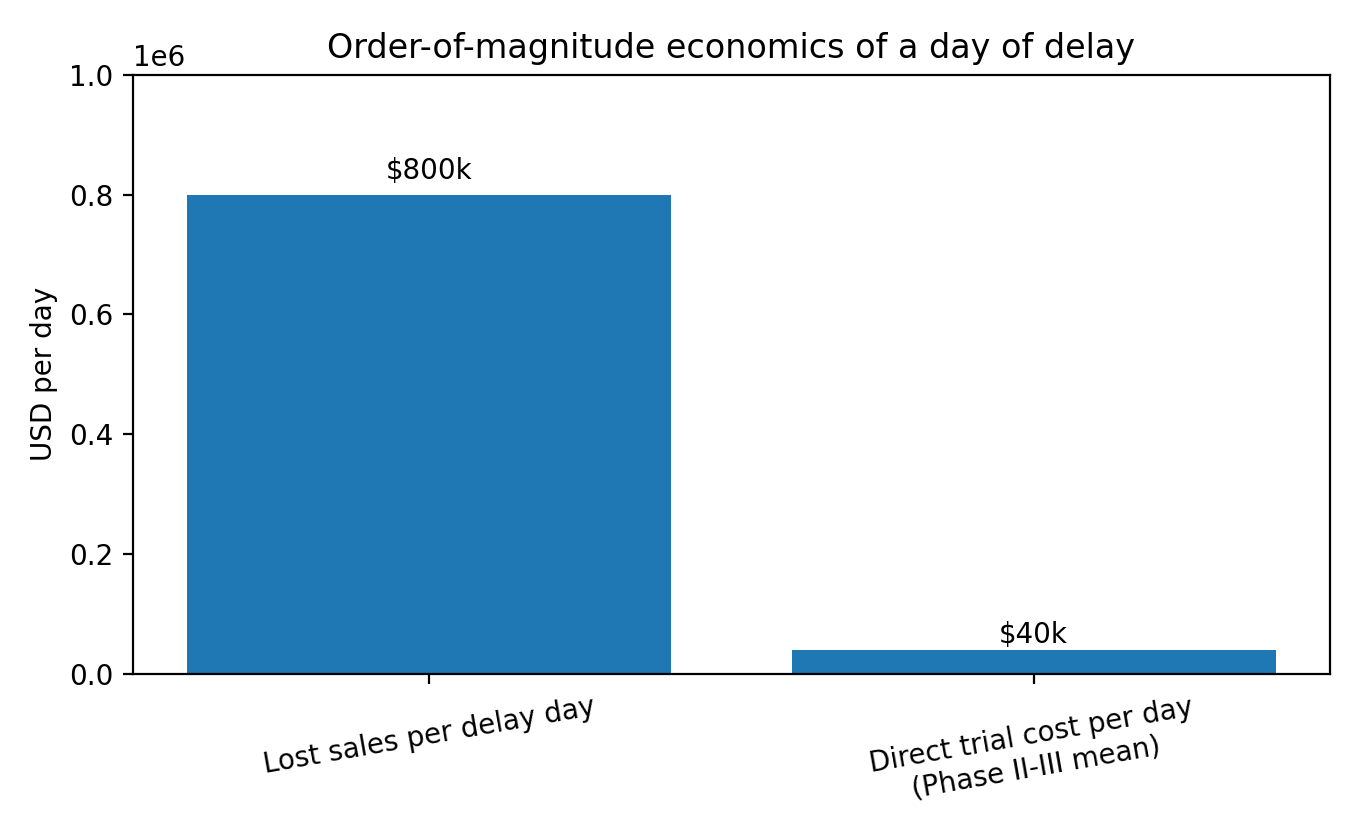
Today, most organizations address this with a mix of internal pharmacometrics/clinical pharmacology teams, consulting/CRO support, and point tools: systematic review software for screening, spreadsheets for extraction, and bespoke scripts for analysis. This works, but it’s slow, expensive, and hard to scale. Systematic literature reviews are widely described as labor-intensive and often take months; one study of Cochrane reviews reported a median update time of about 35 months. Even when teams are doing narrower evidence syntheses (e.g., model-based meta-analysis), the bottleneck is still data curation and standardization across heterogeneous studies.
Shortcoming of current solutions:
Manual extraction is the limiting reagent: plots and tables in PDFs do not behave like databases, so throughput scales linearly with expert hours.
Generic LLM tools can summarize text but struggle with domain-specific structure, multimodal extraction (PK/PD plots, Kaplan-Meier), and auditability needed for high-stakes decisions.
Outsourcing can move the work but not eliminate it; it also increases iteration latency when assumptions change (common in trial design).
Point solutions optimize a step instead of the loop. The expensive part is the full loop: retrieve -> extract -> normalize -> model -> decide -> repeat.
Solution: turning messy literature into model-ready signal
Trial design decisions are only as good as the external evidence substrate they sit on, and that substrate is mostly trapped in unstructured artifacts (PDFs, figures, tables, registry pages). If you can industrialize the conversion of that substrate into analysis-ready data, you unlock faster iteration and better calibration.
Delineate describes itself as a one-stop shop with three pillars: (1) agentic search and triage over PubMed and ClinicalTrials.gov; (2) computer-vision extraction from charts/tables/text with >80% end-to-end fidelity; and (3) a web-based modeling workstation with R, Python, and Julia pre-installed.
The value proposition:
End-to-end loop coverage: it targets the full evidence-to-model loop, not just retrieval or summarization.
Multimodal extraction: explicit focus on numbers locked inside PK/PD plots and Kaplan-Meier curves, where many generic tools fail.
Domain packaging: a modeling workstation (R/Python/Julia) pushes the output directly into the environment where scientists already work.
Validation posture (implied): the company emphasizes fidelity and the ability to standardize units, dosing arms, and covariates, i.e., the details that decide whether a model is usable.
Durability will depend on whether Delineate can turn early product wedges into compounding advantages. Three moat candidates are plausible:
Data compounding: each new dataset-building engagement yields edge cases, labeling rules, and normalization logic that improve the system for the next customer.
Workflow embedding: once a team’s trial-design process depends on Delineate’s evidence pipelines, switching costs become process costs (not just software costs).
Trust capital: in regulated environments, reliability and auditability are assets. If Delineate becomes the trusted extractor for plots/tables, that reputation compounds.
The natural product arc is from project-based evidence synthesis to a continuously updating living evidence model layer. That would look like agents that keep a disease-area knowledge base current, re-run meta-analyses when new trials land, and surface design recommendations as assumptions shift.
Consider a common scenario: a team needs to pick dose and endpoints for a Phase II study in a crowded indication. They must understand historical response rates, placebo drift, dosing regimens, and covariate effects across heterogeneous trials. Traditionally, this becomes a months-long effort of screening, extraction, and spreadsheet archaeology. Delineate’s pitch is to compress this by automating search/triage and extracting numeric endpoints from plots/tables into a standardized dataset, so modelers can run trial simulations sooner and iterate more times before committing to protocol.
Delineate sits between public evidence sources (PubMed, patents, ClinicalTrials.gov) and the internal analytics stack (R/Python/Julia, dashboards, and trial simulation tooling). It is best thought of as an evidence ingestion + normalization layer that feeds pharmacometric and clinical strategy workflows.
Use cases
Dose selection and regimen design using external comparators and exposure-response evidence.
Protocol design: inclusion/exclusion criteria tuning, endpoint selection, and powering assumptions informed by historical trials.
Competitive landscape: building structured datasets on a drug class (Delineate claims work on the “largest dataset on a drug class ever constructed” for a customer).
Regulatory and translational strategy: supporting model-informed drug development artifacts (MBMA/QSP/PBPK inputs) with faster evidence extraction.
Why wasn’t this built before now?
Delineate’s timing is aligned with three converging shifts: (1) multimodal foundation models make extraction from messy scientific artifacts economically feasible; (2) regulators are encouraging (and in places operationalizing) greater use of computational models and new approach methodologies; and (3) biopharma R&D is large enough, and pressured enough, that small cycle-time improvements are worth real money.
Until recently, the cost/quality frontier for NLP and computer vision made reliable extraction from heterogeneous scientific PDFs a bespoke ML research problem more than a product. Even when extraction worked, the last-mile normalization (units, arms, covariates) still required heavy human review, so ROI was fragile. Agentic workflows (systems that can plan and iterate across tools) became practical only once foundation models were good enough and cheap enough to go from chatbots to running as loop engines.
The category evolved in layers: (a) manual literature reviews; (b) systematic review workflow tools (screening and citation management); (c) semi-automated extraction attempts; and (d) the recent jump where large language models become usable components in extraction pipelines.
Recent trends that made Delineate’s solution possible:
Regulatory pull toward human-relevant modeling: FDA’s roadmap discusses NAMs and highlights in silico models such as PBPK and QSP as part of an integrative strategy.
Economics of time: with delay-day value in the hundreds of thousands of dollars on average, compressing cycles is meaningful even if it doesn’t change ultimate outcomes.
Scale of the substrate: global pharma R&D spend is measured in the hundreds of billions of dollars per year, creating budget headroom for tools that save months of expert time.
Market potential: how big is ‘evidence to models’?
The primary buyer is a biopharma organization with meaningful clinical development activity and a culture of quantitative decision support, typically clinical pharmacology/pharmacometrics, biostatistics, clinical development strategy, and (in some cases) medical affairs or competitive intelligence. The market is best described as the evidence and modeling layer of MIDD / trial design: tools and services that transform external evidence into simulation-ready inputs.
Delineate is selling a new operating cadence: treat external evidence as continuously refreshable data, not as a one-off literature review deliverable. If successful, that reframes the category from systematic review tooling to living evidence infrastructure.
The customer profile they cater to:
Teams making high-stakes design choices under uncertainty (dose, population, endpoints, comparators).
Organizations that already run pharmacometric or systems models but are bottlenecked by data curation.
Sponsors under time pressure (e.g., competitive indications, accelerated development paths), where faster iteration has option value.
Delineate is partnered with two, top-ten pharma companies, and collaborations with major pharma leading to impact (datasets, meta-analyses, copilots).
A top-down way to size the ceiling is to start with global pharma R&D spend and then carve out the portion related to clinical trials and the subset that is realistically spendable on evidence/modeled decision tooling.
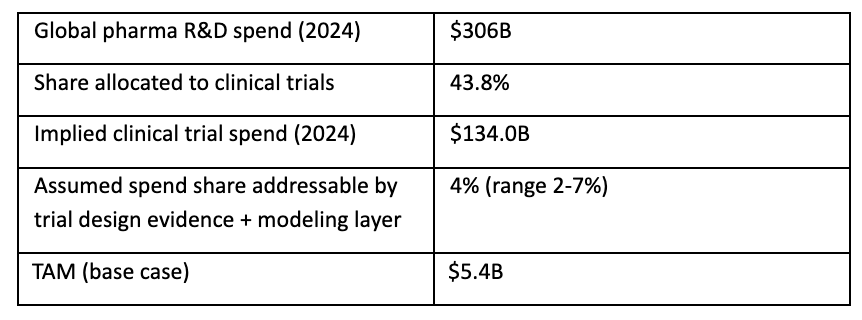
This yields a base-case TAM of roughly $5.4B/year for the evidence + modeling layer inside clinical trials, with plausible bounds from $2.6B (2%) to ~$9.4B (7%). This is consistent in order-of-magnitude with Delineate’s own $10B market framing.
Bottoms-up, SAM is constrained by which organizations have (or can justify) dedicated MIDD/evidence synthesis capacity. A conservative build:
Target accounts: ~250 (top 50 pharma + ~200 mid-size pharma/biotech with active clinical programs).
Average annual spend on Delineate-style tooling/services per account: ~$0.8M (mix of subscription + dataset projects).
Implied SAM: ~$200M/year (range ~$120M to ~$400M depending on scope and pricing).
SOM is a go-to-market and execution question. A reasonable five-year target for a focused enterprise startup might be 15-30 customers at $0.5-1.0M ARR-equivalent, implying $8-30M in recurring revenue, plus project revenue on top.
Competition: alternatives, substitutes, and the status quo
In practice, Delineate competes with any solution that gets a team from question to analysis-ready dataset faster. The closest substitutes fall into three buckets:
Pharmacometrics / MIDD platforms and vendors (tools for simulation/modeling) that may incorporate literature workflows.
Evidence synthesis tooling (systematic review management, extraction, and knowledge platforms) that are expanding into automation and LLM-assisted workflows.
Specialist consultants/CROs that deliver MBMA/QSP/PBPK and trial design support as a service.
The default competitor is inertia plus spreadsheets.
Delineate’s most credible winning path is a wedge-and-expand play:
Wedge: become the fastest credible way to build fit-for-purpose clinical evidence datasets (especially from plots/tables) for a specific decision (dose, comparator, endpoint strategy).
Expand: attach a modeling copilot/workstation so the dataset immediately turns into trial simulations and decision artifacts (reducing handoffs).
Land and deepen: codify normalization rules and disease-area templates, turning projects into repeatable products (compounding).
Defend: invest in quality control, provenance, and audit trails so outputs are trusted in regulated, high-stakes settings.
Delineate’s competitive advantages:
Multimodal extraction focus (PK/PD plots, Kaplan-Meier, complex tables) with fidelity claims.
Agentic triage against custom inclusion criteria, aiming to reduce screening burden and make evidence review more systematic.
Integrated analysis environment (R/Python/Julia workstation), shortening the time from extracted data to model output.
Credibility signaling through MIT CSAIL ecosystem and public presentations describing trial-design impact.
Key risks in the landscape:
Fast followers: general-purpose AI copilots and incumbent vendors can add good enough extraction features, compressing differentiation.
Proof burden: in clinical settings, small error rates in extracted numbers can create large downstream model errors. Delineate must win on reliability and speed.
Buyer friction: procurement and validation cycles in pharma are slow; the product must show an obvious ROI and be easy to pilot.
Product: anatomy of an evidence-to-model machine
Delineate’s product portfolio currently looks like a platform-plus-services bundle:
Agentic search & triage: autonomous agents sweep PubMed and ClinicalTrials.gov, cluster and rank studies against custom inclusion criteria.
Extraction engine: layout-aware computer-vision models extract numbers from PK/PD plots, Kaplan-Meier curves, and complex tables; includes auto-standardization of units, dosing arms, and covariates.
Model generation & analysis copilot: a web-based workstation with R/Python/Julia to generate models and perform analysis.
Bespoke AI services: building fit-for-purpose datasets for specific pharma decisions.
A reasonable high-level architecture, consistent with Delineate’s public descriptions, is:
Ingestion: pull candidate documents/trials from PubMed, patents, and ClinicalTrials.gov.
Triage: agentic clustering/ranking against inclusion criteria; human review for acceptance.
Extraction: multimodal parsing of text/tables/figures; number extraction from plots; entity linking.
Normalization: unit harmonization, arm mapping, covariate standardization, and provenance tracking.
Delivery: export to a modeling environment (web workstation) and generate analysis artifacts (meta-analyses, simulations, dashboards).
Delineate’s inferred roadmap consistent with the product wedge and the needs of enterprise pharma buyers:
Validation & auditability: expand extraction fidelity, add per-field confidence scoring, and produce traceable provenance for every datapoint (critical for trust).
Disease-area templates: pre-built pipelines for high-volume indications (oncology, immunology, metabolic) to shorten time-to-value.
Self-serve + collaboration: move from bespoke dataset projects toward a repeatable workflow that scientists can run and iterate themselves.
Integration: connectors to internal data lakes, trial operations tools, and modeling systems; support for regulatory-facing artifacts.
From evidence to recommendation: agents that not only extract but propose trial design choices with clearly stated assumptions and sensitivity analysis (human-in-the-loop).
Business model: charging for speed, trust, and audit trails
The most plausible business model is enterprise software plus services: use high-value dataset and modeling engagements to land accounts, then convert workflows into recurring subscriptions as usage becomes embedded.
Delineate’s revenue model:
Enterprise subscription for platform access (agentic search, extraction, workstation).
Project-based services for bespoke dataset construction, model development, and pilot deployments.
Potential usage-based components (e.g., per-document extraction, per-dataset refresh) once self-serve workflows mature.
Delineate has not publicly disclosed pricing. For scenario modeling, I assume $0.5-1.0M per mature enterprise account-year (software + services blended). If an account stabilizes at ~$0.8M/year and retains 4-6 years, gross LTV can land in the $3-5M range before discounting.
Delineate’s sales and distribution model:
Enterprise direct sales to clinical development, quantitative pharmacology, and R&D strategy leaders.
Land-and-expand via pilots tied to specific trial decisions (dose selection, external comparator, endpoint strategy).
Channel partners: CROs and specialist consultants can be distribution multipliers, but only if Delineate’s tooling reduces their cost structure rather than cannibalizing it.

Team: scientific taste meets engineering throughput
The company is founded by Emily Nieves (CEO) and Jawad Iqbal (CTO). Nieves frames the company as an extension of her research at MIT at the intersection of AI and systems pharmacology. The founder-market fit story: pharmacology + AI + the willingness to grind the unglamorous data pipeline. Delineate is blending pharmacology and data science to reduce trial errors.
Vision: if it works, Delineate becomes the trial-design OS
The three existential risks (and how to mitigate)
Trust failure: a high-profile extraction error that cascades into a wrong decision could kill adoption. Mitigation: audit trails, conservative confidence, human-in-the-loop reviews.
Platform squeeze: incumbents or foundation-model vendors bundle similar capabilities. Mitigation: specialize deeply, own domain evaluation data, and integrate with workflow.
Scope creep: trying to solve ‘all of drug development’ too early. Mitigation: keep the wedge sharp; expand only when usage and retention justify it.
In the best case, Delineate becomes the evidence-to-simulation layer behind clinical development decisions: a living system that continuously ingests new trials and publications, refreshes structured datasets, re-runs meta-analyses and trial simulations, and surfaces decision-relevant deltas.
That vision is closer to an operating system for trial design: agents + data plumbing + validated modeling workflows.
What this unlocks
Higher hypothesis velocity: explore more protocol variants before committing, potentially reducing avoidable trial failures.
Faster translation of external evidence into internal models, narrowing the gap between published knowledge and decisions.
A path toward regulator-grade computational artifacts as NAMs and in silico models become more central.