
Databricks vs. the Fragmented Data Stack
A field guide to the company trying to unify data, governance, and AI on the modern enterprise stack.

Why the data stack broke
The modern enterprise data stack is an archeological dig: transactional systems (ERP/CRM), SaaS exhaust, files, logs, and streaming events. To do anything useful, teams must ingest, clean, govern, and serve this data across multiple audiences - engineers, analysts, scientists, and now AI builders.
In practice, customers report four recurring pains:
Fragmentation: separate systems for lakes, warehouses, ETL/orchestration, catalogs, feature stores, vector databases, and model serving leads to brittle interfaces and duplicated data.
Governance debt: permissions, lineage, and auditability often lag reality, which slows access and raises risk (compliance, privacy, data exfiltration). Unity Catalog exists because this pain is chronic.
Latency mismatch: analytics stacks were built for batch BI, but AI agents and operational workflows need fresh data and a place to write state (memory, decisions, approvals) without a separate OLTP silo. Lakebase is explicitly framed as a response.
Iteration friction: building and improving models/agents requires repeatable evaluation, observability, and rollback - the same discipline as software engineering, but most stacks treat it as an afterthought.
Most organizations patch together one of three patterns:
Classic split: data lake (cheap storage) + data warehouse (fast SQL) + bespoke ML stack, stitched by ETL/reverse-ETL and catalogs.
Cloud-native warehouse-first: warehouse as the center of gravity, with external ETL/ELT, catalogs, and ML tools integrated via connectors.
Platform consolidation: a single vendor platform (or two) chosen to reduce integration surface area, with remaining tools as edge integrations.
These patterns fail in predictable ways:
Integration tax: every connector becomes a reliability problem, and every best-of-breed decision becomes an operating model. The bill arrives during incidents and audits.
Lock-in without leverage: customers end up locked into a toolchain without getting a coherent system. (Switching costs go up; productivity does not.)
AI amplifies the pain: governance requirements become stricter (models must be auditable), data freshness matters more, and the system must support read-reason-write loops (agents) rather than read-only analytics.
The Lakehouse as the unifying substrate
Databricks’ core insight was that the data lake vs data warehouse split is artificial in a cloud world. If you put reliable table management (ACID, schema evolution, time travel) on top of low-cost object storage, you can run BI, ETL, and ML on the same data without copying it into a separate warehouse. Delta Lake (open source) and the lakehouse paradigm are the storage layer expression of that insight.
The 2023-2026 evolution is a second insight: a platform is storage, compute, governance, and intelligence. Databricks now frames the platform as a Data Intelligence Platform built on a lakehouse, with a data intelligence engine and Unity Catalog as the central governance layer.
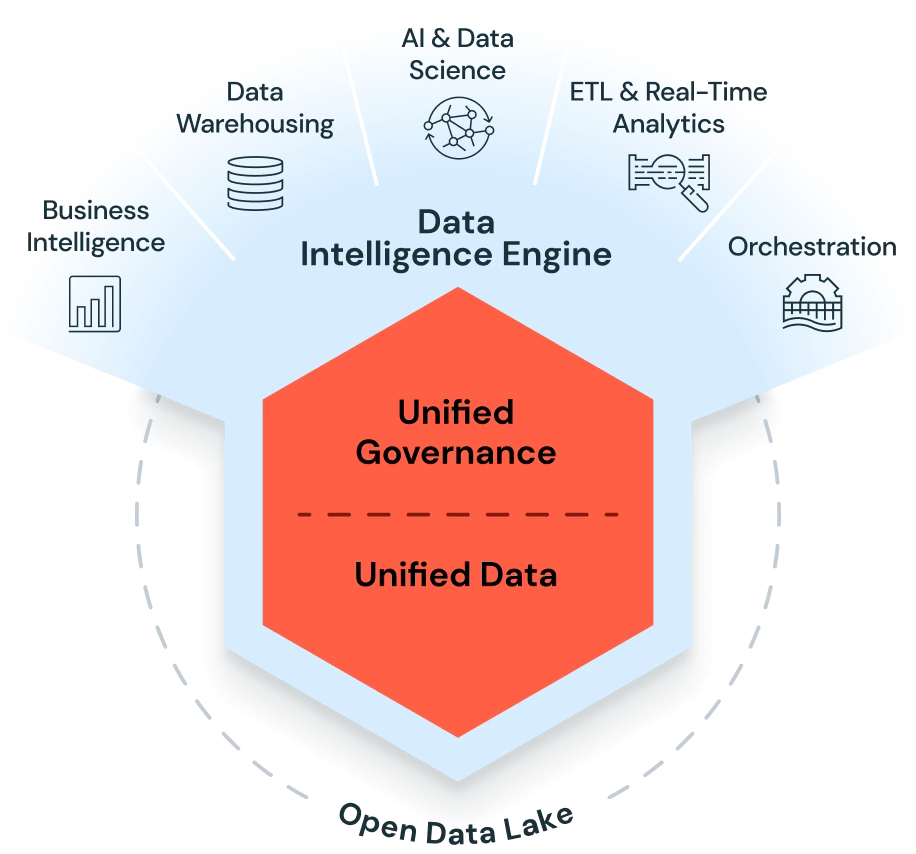
The differentiation is the integration boundary. The platform aims to minimize the number of hand-offs between systems.
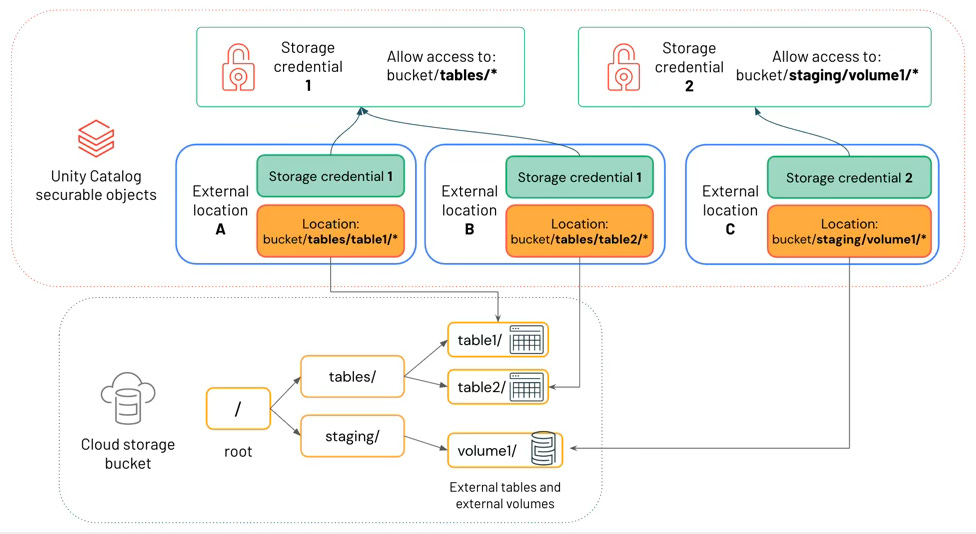
Unified governance across data + AI assets: Unity Catalog is positioned as one security and metadata plane for tables, files, functions, and models.
Open formats with managed performance: Databricks leans on open projects (Spark, Delta Lake, MLflow) while adding proprietary performance layers (Photon) that are turn on, no code changes.
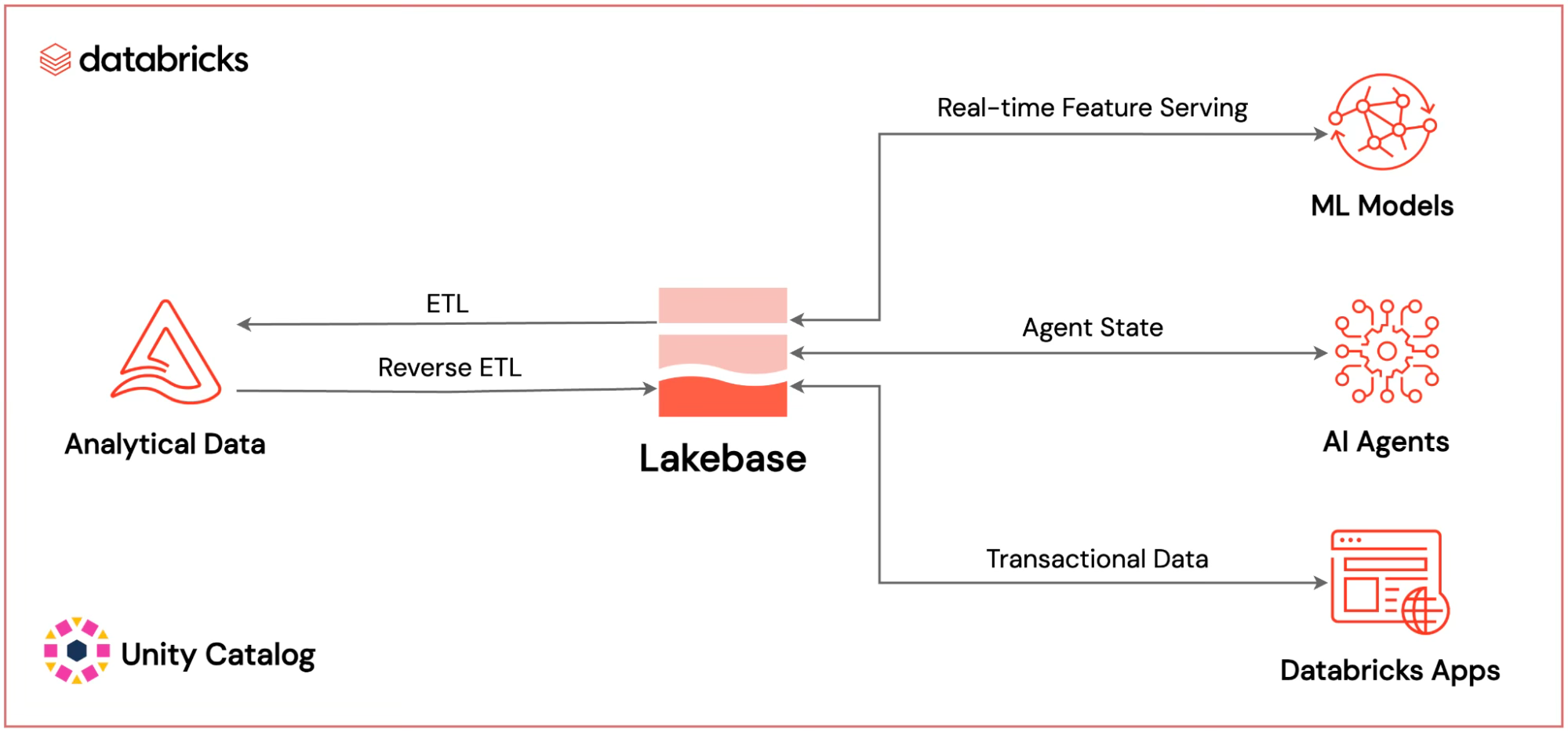
From analytics to applications: Databricks Apps (serverless app hosting) and Lakebase (managed Postgres) move the platform from insights to actions.
AI lifecycle discipline: MLflow 3.0 and Mosaic AI components focus on evaluation, observability, governance, and controlled access to models via a single gateway.
Endurance comes from compounding advantages: data gravity, governance gravity, and workflow gravity.
Data gravity: once core datasets live in Delta tables and feed many teams, copying them elsewhere is expensive and risky.
Governance gravity: when Unity Catalog becomes the system of record for permissions, lineage, and auditing, migrating away is an identity and compliance rewrite.
Workflow gravity: as more workloads run inside one platform (ETL, BI, feature engineering, model serving, apps, OLTP), the platform becomes the default place to build - and the default place to buy.
Databricks is delivered as a managed service on major clouds. Architecturally, it separates a control plane (managed by Databricks) from compute and storage that run in the customer’s cloud account, with options for classic clusters and serverless compute.
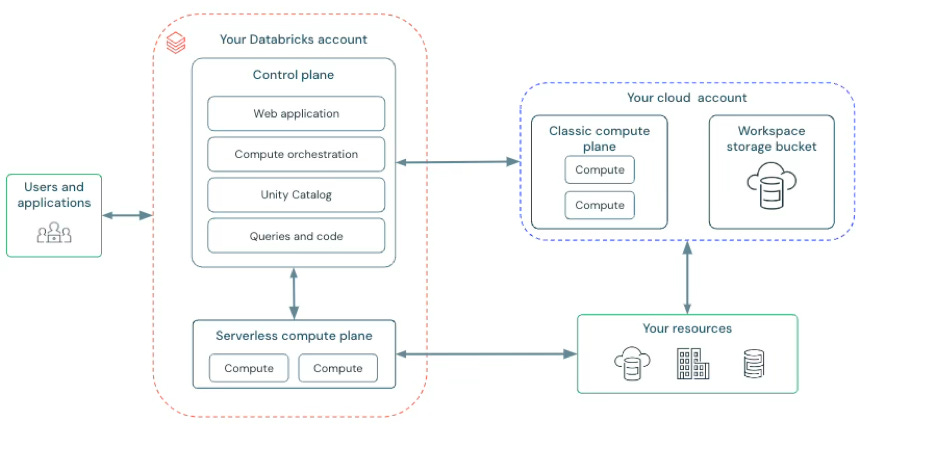
Before: data pipelines copy data from OLTP → lake → warehouse; models train in a separate environment; governance is inconsistent; apps read stale data.
After: data lands once in the lakehouse; BI, ETL, and ML share governed tables; models and agents are evaluated and served with the same governance; apps and (increasingly) OLTP live in the same platform.

Cloud, open standards, and the AI demand shock
Two things became true at the same time: cloud object storage made one copy of data economical, and AI made governed, reusable data existential.
The lakehouse and its successors required prerequisites that were missing in prior eras:
Cheap, durable, elastic storage: object storage (S3/ADLS/GCS) changed the economics of keeping raw + curated data online.
Separation of storage and compute: cloud infrastructure made it normal to scale compute independently - and to adopt serverless patterns.
Table reliability on lakes: open table formats and transaction logs (e.g., Delta Lake) were needed to make lakes safe for BI and ML.
Governance as a first-class system: enterprise adoption (especially regulated industries) demanded consistent access control and auditing across tools and clouds.
Historical evolution of the category:
Hadoop era: cheap storage + batch compute, but operational complexity and slow iteration.
Spark era: faster compute and a common API for ETL/ML, initially on clusters; Databricks was born commercializing this.
Cloud warehouse era: managed performance, but data duplication and integration tax.
Lakehouse era: open storage + managed compute + reliability on the lake, reducing copies.
Data intelligence / agentic era (current): systems must not only analyze but also act; agents require state, governance, and evaluation loops.
Recent trends that make the solution possible:
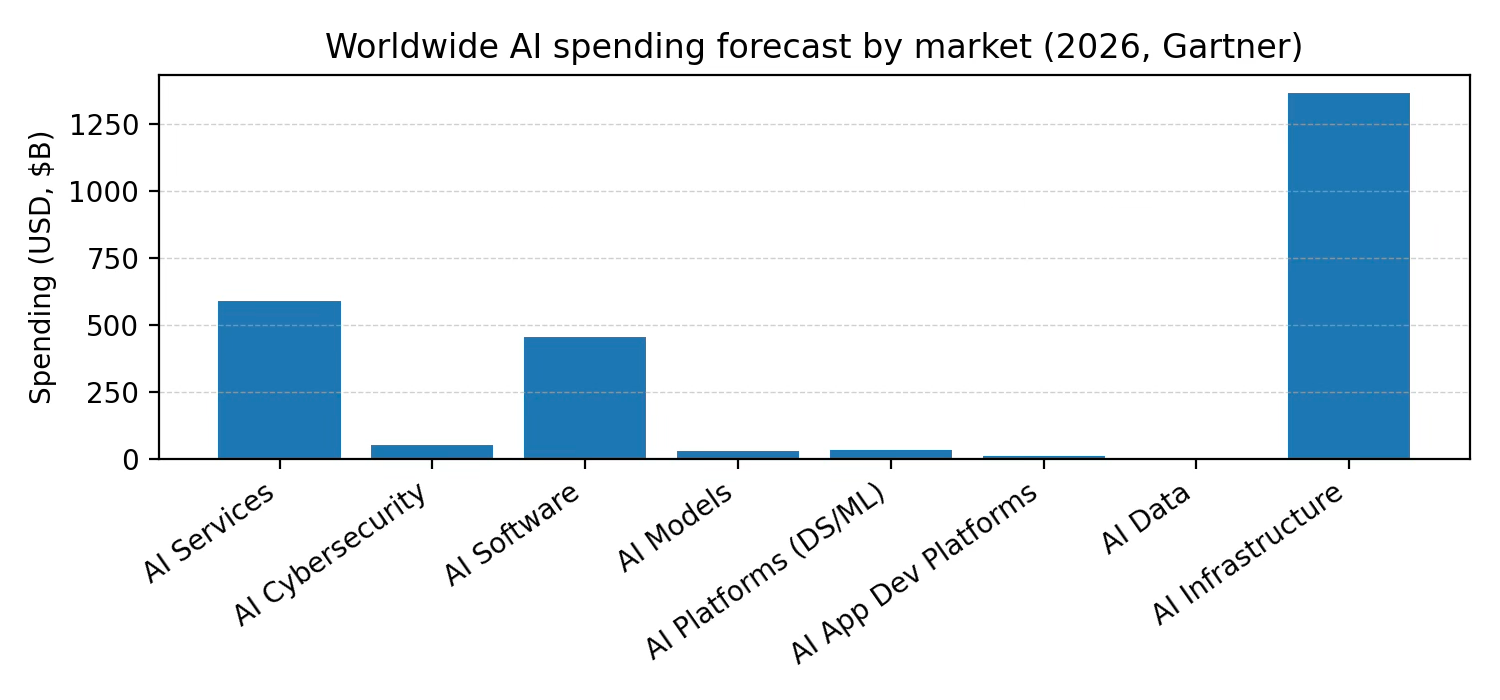
Enterprise GenAI adoption: spending on AI is forecast to reach $2.52T in 2026, with infrastructure and software as major components.
Shift to consumption/serverless: customers want pay-for-use and less ops; Databricks emphasizes per-second usage and serverless compute.
Open ecosystems matter: customers resist lock-in; Databricks emphasizes open projects and open protocols (Spark, Delta, MLflow, Delta Sharing).
AI agents push OLTP-OLAP convergence: AI workflows need fast reads/writes plus historical context; Lakebase and Apps are Databricks’ answer.
Sizing the data + AI platform opportunity
Databricks sells primarily to organizations with large, heterogeneous data estates, meaningful governance/compliance requirements, and a mandate to operationalize analytics and AI. The customer base is enterprise: Databricks reports that more than 20,000 organizations worldwide rely on it, including large global brands, and over 60% of the Fortune 500.
Databricks has repeatedly tried to rename the playing field:
Lakehouse: a unified architecture that collapses the lake/warehouse split.
Data Intelligence Platform / Engine: the claim that AI-driven semantics + governance become the central primitive for how organizations interact with data.
Data Intelligent Applications: a category framing that pulls Databricks toward application development and operational systems.
Lakebase / lakebases: a new operational database class designed to converge OLTP and the lakehouse.
A useful segmentation:
Databricks’ enterprise customers across industries: examples include adidas, AT&T, Bayer, Block, Mastercard, Rivian, Unilever. Toyota publicly announced a unified data and AI platform (vista) built on Databricks.
TAM (top-down): strategic addressable spend
Databricks is expanding beyond analytics into operational databases. Its Lakebase launch describes operational databases (OLTP) as a $100-billion-plus market. Separately, Gartner forecasts worldwide AI software spending of ~$452B in 2026. A simple strategic TAM (with acknowledged overlap) is therefore >$552B in 2026 dollars.
SAM (bottom-up): what is realistically in-scope for Databricks’ current product + GTM
Databricks reported a $4.8B revenue run-rate and more than 20,000 organizations using the platform. A crude implied average is ~$240k annual run-rate per customer (4.8B / 20k). If we define the near-term SAM as 50k-200k organizations globally that can sustain ~$250k/year on a unified data+AI platform, the SAM range is ~$12B-$48B annually.
SOM: current penetration (observable)
On the same strategic TAM framing (>~$552B), Databricks’ current reported run-rate (~$4.8B) implies <1% share (~0.9%). The more relevant implication is that even large growth can occur without requiring unrealistic market share assumptions - but only if Databricks continues to expand product scope and wallet share.

Where Databricks wins and loses
Direct competition is mostly in the analytics warehouse + data platform layer:
Snowflake (cloud data warehouse + data cloud ecosystem)
Cloud-native warehouses: BigQuery, Redshift, Synapse/Fabric, Oracle, Teradata (in cloud or hybrid)
Unified platforms: Microsoft Fabric (end-to-end analytics), Google Cloud analytics stack, AWS analytics stack
Indirect competitors / alternatives include:
DIY open-source lakehouse: Spark + Iceberg/Delta + Trino + Airflow + dbt + catalog + MLOps, run and integrated in-house.
Best-of-breed modern data stack: Fivetran/Airbyte + dbt + warehouse + separate feature store + separate vector DB + separate model serving.
Operational database incumbents: Postgres/MySQL variants, Aurora, Spanner, SQL Server, etc., especially as Databricks pushes into OLTP via Lakebase.
Databricks’ plan to win has three recurring elements:
Consolidate workloads on one governed foundation: lakehouse + Unity Catalog as shared substrate.
Make AI practical in the enterprise: Agent Bricks + AI Gateway + MLflow + model serving to reduce time-to-production and increase reliability.
Own the action layer: Apps + Lakebase to move from analytics outputs to real applications and agent workflows.
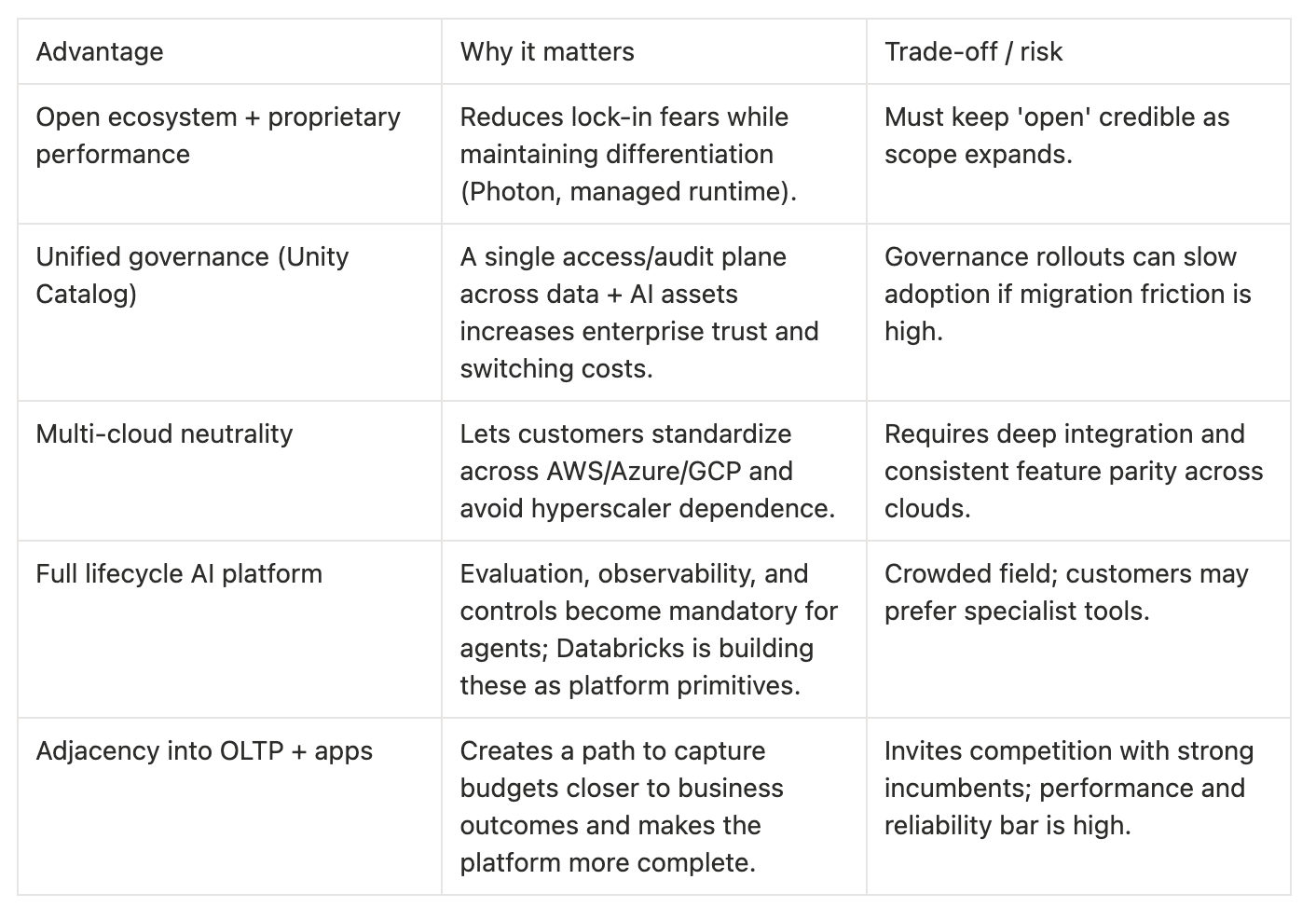
Competitive advantages (and their trade-offs):
What’s shipped, what’s coming
The Databricks form factor is a managed cloud platform deployed into customer cloud accounts, with a control plane managed by Databricks and compute/storage in the customer environment.
Core platform layers
Storage + table management: Delta Lake (open source) and lakehouse storage patterns.
Compute: Databricks Runtime (Spark-based) plus Photon vectorized engine for faster SQL/DataFrame workloads.
Governance: Unity Catalog for access control, auditing, lineage, and discovery across workspaces and assets.
Sharing ecosystem: Delta Sharing and Databricks Marketplace, framed as open protocols/marketplaces for zero-copy sharing.
Workload products (selected)
Data engineering & orchestration: Lakeflow Jobs; Lakeflow Spark Declarative Pipelines (formerly Delta Live Tables).
Data warehousing: Databricks SQL (now >$1B run-rate) and warehouse performance investments.
AI / GenAI: Agent Bricks; Mosaic AI Gateway; Mosaic AI Model Serving; Vector Search; MLflow 3.0 for evaluation and observability.
Application development: Databricks Apps for serverless deployment and management of data/AI applications.
Operational database: Lakebase (serverless Postgres integrated with the lakehouse).
Databricks’ priorities:
Invest in Data Intelligent Applications via three strategic products: Lakebase (system of record), Databricks Apps (UX layer), Agent Bricks (agent layer).
Continue to scale AI products (already >$1B run-rate) and reduce friction via partnerships like OpenAI integration.
Evolve the data engineering surface into more declarative, integrated pipelines (Lakeflow) and align with upstream Spark declarative pipelines.
Expand Lakebase footprint (GA across more regions/clouds; compliance certifications).
Ongoing M&A to add primitives: Neon (OLTP engine), Tabular (Iceberg), Tecton/Fennel (feature engineering), Mooncake (storage acceleration).
Consumption economics and go-to-market
Databricks is a platform business with consumption-based economics: expand workloads inside the customer until the platform becomes the default substrate for data and AI. The reported net retention rate (>140%) suggests expansion within existing customers is a primary growth engine.
Revenue model
Usage-based (consumption) revenue tied to compute and platform services (DBUs and associated pricing constructs).
Enterprise subscriptions/commitments (committed spend) and platform add-ons (e.g., AI features, governance, serving).
Professional services and partner ecosystem contributions (implementation, migration, accelerators).
Databricks positions DBUs (Databricks Units) as a way to meter compute usage, with product-specific SKUs and options for serverless offerings. In practice, large customers tend to negotiate committed-use discounts and enterprise agreements.
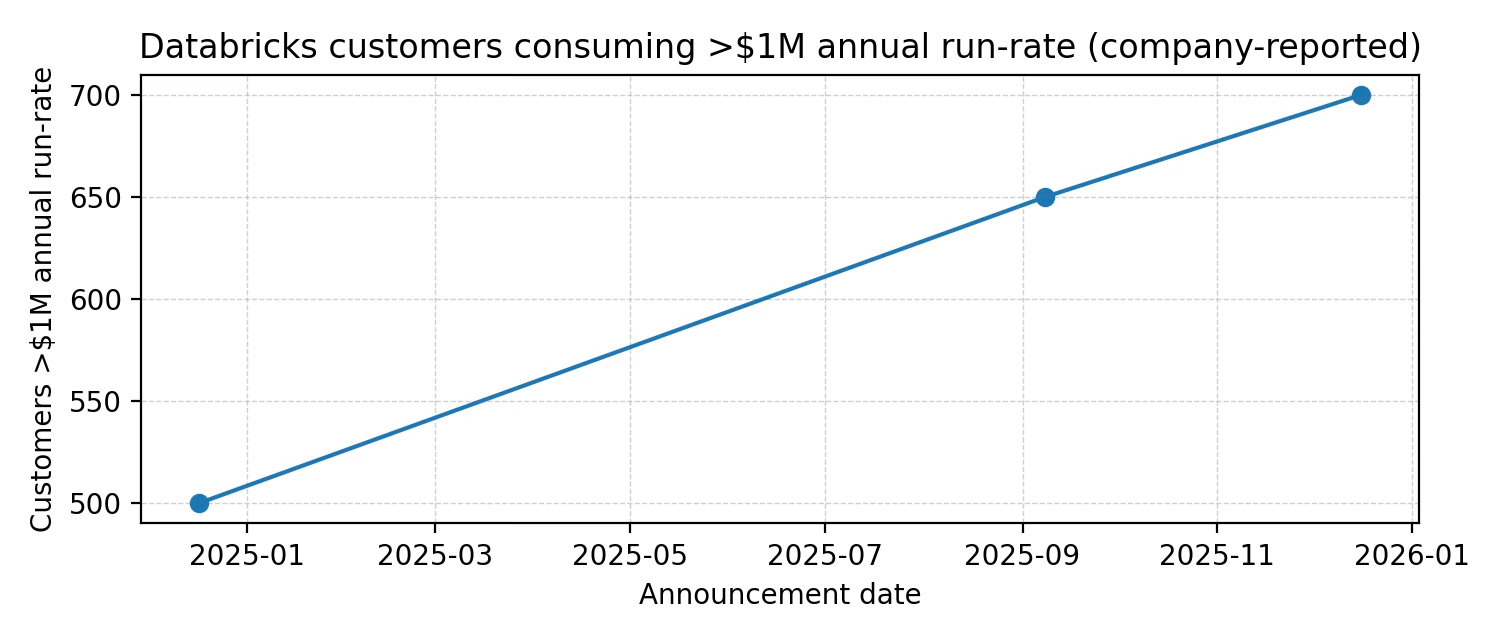
As of Dec 2025 it reports >700 customers consuming at >$1M annual revenue run-rate and net retention >140%. This supports a common enterprise SaaS pattern: a long tail of small users plus a meaningful (and growing) set of very large accounts.
Sales & distribution model
Enterprise direct sales (platform land-and-expand).
Cloud marketplaces and co-sell motions with hyperscalers (Databricks is delivered on AWS, Azure, and GCP; procurement often routes through cloud commits).
Partner-led delivery: global SIs and consultancies, increasingly relevant as the platform expands into apps and database modernization.
Databricks highlights a broad set of logos:
Enterprises: adidas, AT&T, Bayer, Block, Mastercard, Rivian, Unilever (plus over 60% of the Fortune 500).
Toyota: unified data and AI platform (vista).
Partner ecosystem for Lakebase deployments (implementation and modernization): Accenture, Wipro, Retool, etc.
Distribution wedge in 2025-2026: Databricks is pushing hard on agents for the enterprise via partnerships. Its OpenAI partnership is positioned to help enterprises build and scale AI apps on proprietary data.
Founders, operators
Databricks was founded in 2013 by the creators of Apache Spark. The founding team includes Ali Ghodsi, Matei Zaharia, Ion Stoica, Reynold Xin, Patrick Wendell, and others from the UC Berkeley ecosystem. This origin matters: Spark is an ecosystem. Commercializing it required equal parts open-source credibility and enterprise execution - a combination that still shapes Databricks’ strategy.
Following the money
Databricks provides several P&L-adjacent signals:
Revenue run-rate: $4.8B during Q3 2025; >55% YoY growth.
Segment run-rates: >$1B AI products; >$1B data warehousing.
Gross margin: in late 2024, Databricks disclosed non-GAAP subscription gross margin >80%.
Large-customer momentum: >700 customers consuming >$1M annual run-rate; net retention >140%.
Balance sheet
Series J: raising $10B of expected non-dilutive financing (completed $8.6B to date at announcement) at $62B valuation.
Series K: $1B at >$100B valuation.
Series L: raising >$4B at $134B valuation; capital expected to support product development, liquidity, and acquisitions.
The endgame: data intelligence everywhere
If Databricks executes, the 2031 product is an operating system for enterprise intelligence:
A unified substrate where operational and analytical data are naturally co-resident (lakehouse + lakebase), reducing the need for ETL and eliminating data staleness as a design constraint.
An enterprise governance layer that treats models, features, metrics, and agents as first-class assets - audited, permissioned, and discoverable like tables are today.
A development experience where building agents is closer to software engineering: evaluation-driven, observable, and deployable with guardrails by default (Agent Bricks + MLflow + AI Gateway).
A marketplace and sharing ecosystem that turns governed data and AI assets into reusable building blocks across organizations (Delta Sharing + Marketplace).
Databricks looks less like a single product and more like an attempt to compress the modern data stack into one coherent system. The strategy is ambitious, but the financial and adoption signals disclosed to date suggest it is working: multi-billion run-rate, positive free cash flow claims, and large-account depth. The decisive question for the next five years is whether Databricks can remain the place where enterprises analyze and build.