
Clado and the People Layer
How “deep research for people” could become infrastructure for recruiting, sales, and sourcing. Part of YC Spring 2025.

Clado is a ground-truth platform for humans that lets teams and developers search for people and enrich their profiles and contact data using natural-language prompts. The company is trying to turn finding the right person into a low-friction primitive, like search for web pages, but for humans, powered by large-scale agentic inference rather than filters.
The durable job-to-be-done is decision-quality. In hiring, outbound sales, and research, the costly mistake is paying with time, missed opportunities, and bad picks. A tool that consistently finds higher-quality lists faster becomes a compounding advantage: better candidates, better conversions, and better feedback loops.
Why Finding People Still Feels Broken
Customers doing recruiting, sales prospecting, or sourcing face three repeating pains:
Discovery cost: turning a fuzzy prompt (“people like X”) into a clean list takes hours of manual iteration.
Precision failure: filters and keywords don’t capture nuance (career trajectory, seniority, domain adjacency, role transitions).
Action gap: even if you find someone, you still need reliable contact data and context to actually act.
Today’s workaround stack looks like:
Incumbent databases and search UIs: LinkedIn Recruiter / Sales Navigator, ZoomInfo, Apollo, etc.
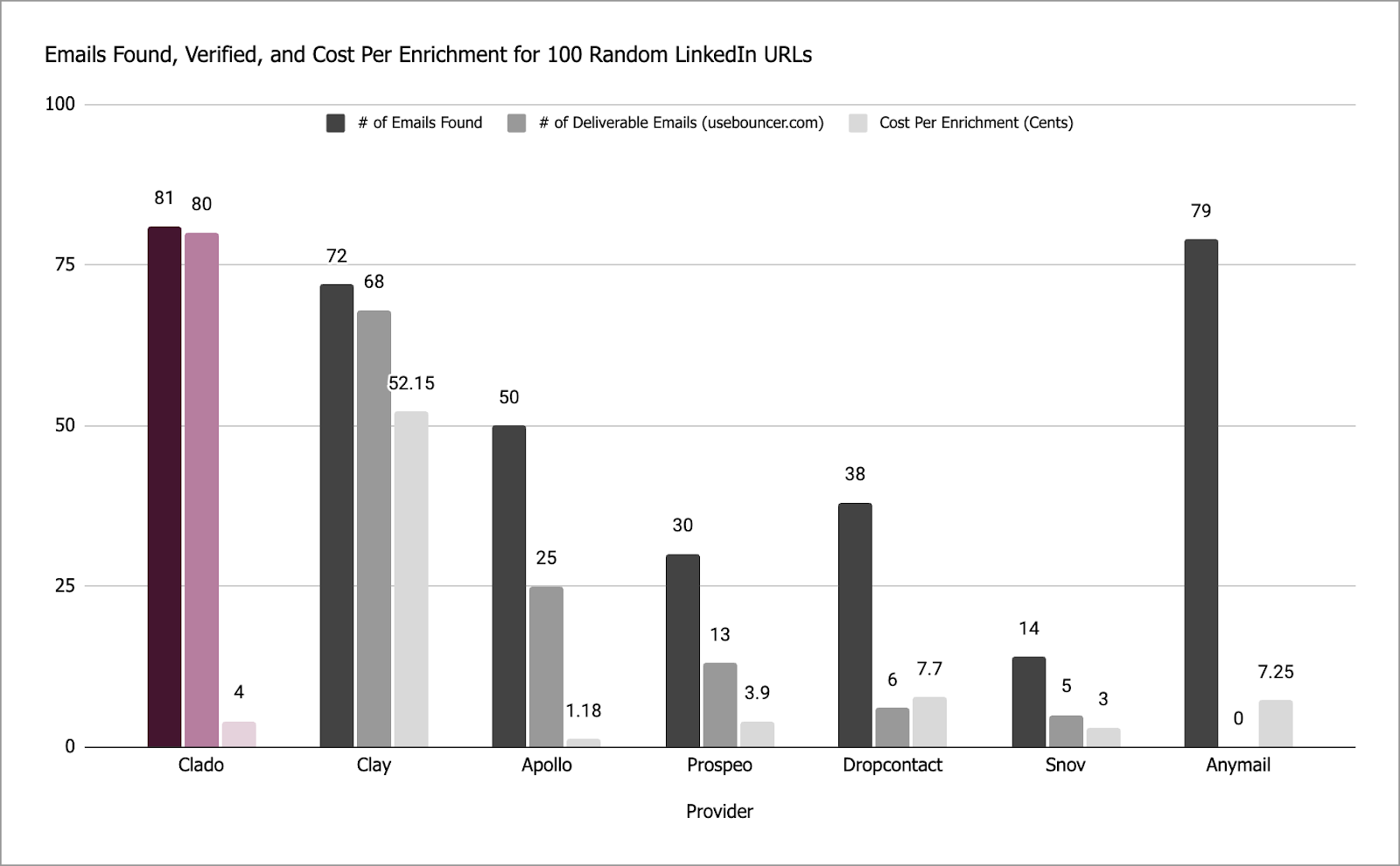
Data enrichment point tools: Clay, Apollo enrichment, Prospeo, Dropcontact, etc.
Manual research: LinkedIn + Google + GitHub + papers + spreadsheets; lots of copy/paste.
The shortcomings tend to be structural:
Filters assume the customer can translate intent into schema. Many can’t. and even experts waste time.
Datasets are partial or stale; accuracy isn’t aligned with user incentives unless verified.
Most tools separate ‘find’ from ‘enrich’ and separate ‘results’ from ‘reasons’, leaving humans to do the last-mile reasoning.
Incumbents monetize scarcity via seats, not outcomes, which can encourage bloat and friction.
From Prompts to Verified Lists
People search is a retrieval + interpretation + verification problem. Clado’s pipeline is natural language input, AI translation to structured criteria, scoring/filtering, and enrichment into structured outputs.
Clado’s core value prop is: “write what you want, and the system does the tedious translation and screening.” Clado contrasts itself with similarity/keyword search by emphasizing massively parallel agents that decide whether each profile matches a prompt.
Endurance hinges on whether Clado compounds advantages over time. The most plausible flywheel is:
More queries → better eval sets → better query-to-criteria models → better results.
Better results → more embedded usage in workflows and products → higher switching costs.
More enrichment outcomes → better provider selection / verification → higher trust.
Clado’s roadmap signals: planned integration of new sources (e.g., org charts and academic research via OpenAlex) and deeper cross-platform linking (GitHub repositories, LinkedIn profiles, other identifiers). That’s a move from “search” to “knowledge graph + verification layer,” which is the natural endpoint if the product is to become infrastructure.
A simple way to see the value is to measure output per unit time: how quickly can a team go from ‘vague prompt’ to ‘actionable list with contacts’? Clado highlights the intended unit: candidate quality relative to time spent sourcing.
Clado sits in three places:
A web UI (“Atlas”) oriented around team workflows (search, filtering, exports, monitors).
A developer-facing API at https://search.clado.ai for embedding search/enrichment into other products.
A data layer that unifies identities across sources into a single “Clado Profile.”
Clado highlights four main use cases: recruiting, sales, venture capital, and custom team workflows:
Recruiting: complex criteria candidate discovery + verified outbound-ready exports.
Sales: hyper-targeted lead generation + contact enrichment + account context.
VC / sourcing: monitors to detect new matches early and build lists by niche criteria.
Developers: programmatic people search and enrichment via API, priced per successful outcome.
Why This Works in 2026
The missing ingredient until recently was was unit economics. Agentic search implies many model calls per query (interpretation, scoring, filtering, verification). That used to be financially absurd. Clado made a before/after cost comparison: a high-end “oracle” approach (using a frontier model) is orders of magnitude more expensive per run than a specialized, trained open model.
Historical evolution of the category:
Phase 1: Directories: static lists, manual vetting, near-zero search expressiveness.
Phase 2: Platform profiles: LinkedIn normalized public professional identity; keyword search + filters dominated.
Phase 3: Data vendors: ZoomInfo/Apollo-era aggregation + enrichment, but still largely filter-based and often noisy.
Phase 4: Agentic search: natural language becomes the interface; the system does translation + verification.
Several trends converge to make Clado’s approach possible:
Better language models: NL → structured query translation is now reliable enough to be productized (with evals).
Cheaper inference + specialization: fine-tuned open models can outperform expensive general models in narrow tasks at far lower cost.
Modern search infrastructure at scale: vector + keyword hybrids (OpenSearch/Elastic style) are mature enough to support huge indexes.
A cultural shift: teams are willing to delegate more ‘research’ to machines, as long as outputs are inspectable and verifiable.
The Business of Finding People
Clado sells into workflows where “find the right person” is either revenue-generating (sales) or value-preserving (hiring, diligence). The closest market buckets are sales intelligence and recruitment software, with an adjacent slice of enrichment/data infrastructure.
Clado’s core customers are:
Recruiting teams doing high-volume sourcing and outbound outreach.
Sales teams doing list building and email enrichment at scale.
Venture capital / sourcing teams who need niche discovery and monitoring.
Developers and data teams embedding people search/enrichment into products.
Some of Clado’s customers include Mercor, Cognition, SevenAI, Greylock, Turing, Augment, and Bolto.
TAM (top-down, category):
Market-sizing for two closest buckets:
Sales intelligence market: $2.95B (2022) projected to $6.68B (2030), CAGR 10.8%.
Recruitment software market: $3.77B (2026) projected to $5.5B (2031).
If you (improperly) sum these as an upper bound for 2026, you get roughly $8.2B. This overstates because of overlap, but it’s a reasonable ceiling for ‘people search intelligence’ in the near term.
SAM (bottoms-up, seat):
A bottom-up view starts with seats that do sourcing/outbound. One US-only proxy:
Human resources specialists employment (US, 2024): 944,300.
Wholesale/manufacturing sales representatives employment (US, 2024): 1,613,600.
If Clado initially targets a subset of these roles (say 20% of HR specialists and 15% of these sales reps) and captures an illustrative $1,200/year in average revenue per active seat, SAM is about $0.52B/year.
SOM (obtainable market):
SOM depends on distribution and platform risks. Using the illustrative SAM above, a 3% SOM is about $15.5M/year. The point is not the exact number, it’s whether Clado can build repeatable distribution and maintain data access durability.
Some companies create new markets. Clado’s ambition is closer to a ‘people layer,’ a programmable substrate that other tools sit on top of, than to a classic SaaS seat product. If that’s true, the relevant TAM expands from ‘recruitment software’ to any workflow that needs verified human identity and context.
The Race to Own People Search
Clado competes across three layers:
Search incumbents: LinkedIn Recruiter/Sales Navigator; various HR/sales platforms bundling search.
Sales intelligence & data: ZoomInfo, Apollo, Clearbit (legacy), Lusha/RocketReach, etc. (data + enrichment).
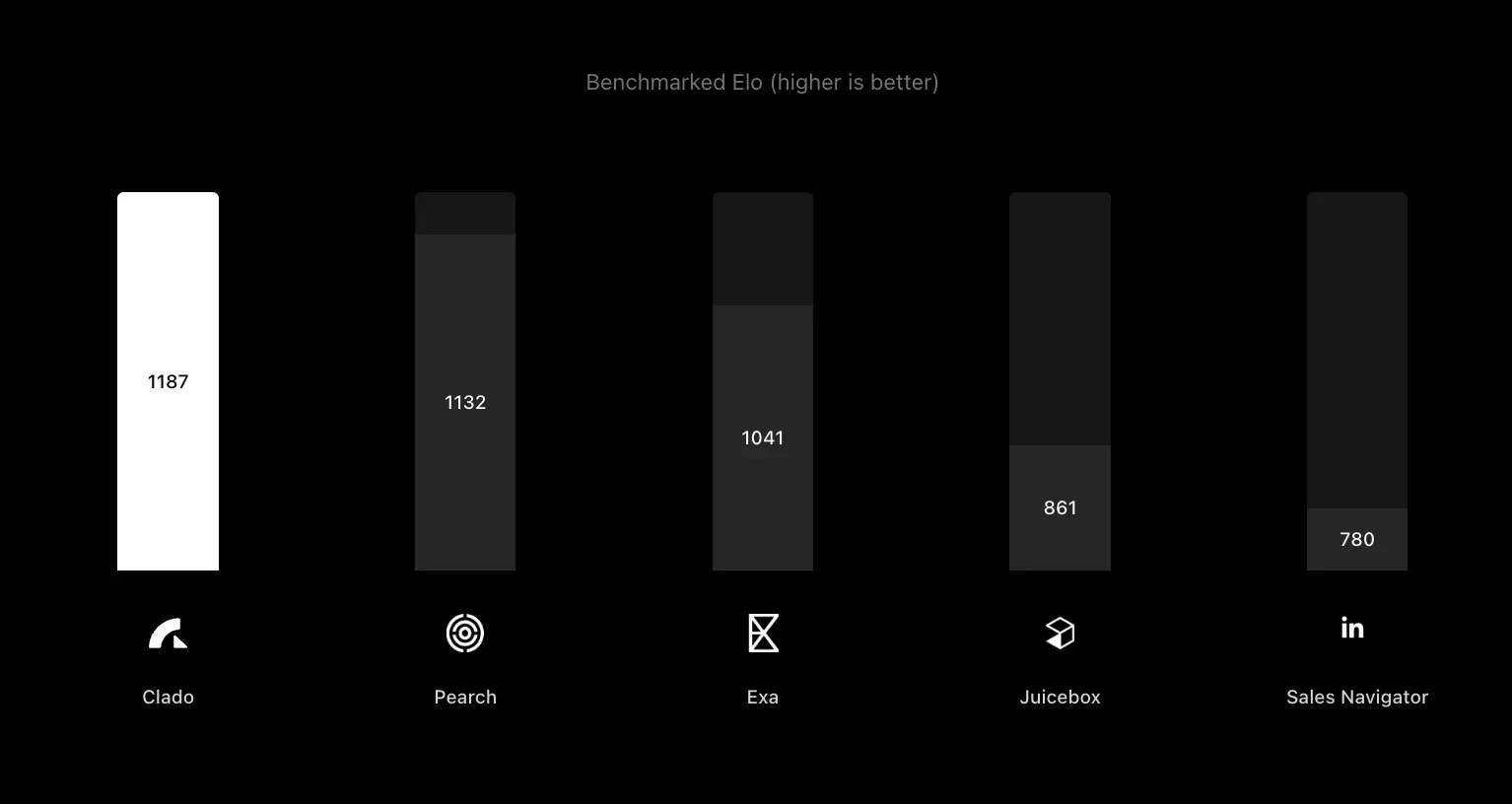
New agentic entrants: Pearch, Exa Websets, Juicebox, and other NL-to-people-search tools (often API-first).
The most common alternative is a spreadsheet, a research assistant, and a Friday afternoon quietly dying in Google tabs. If Clado only wins against tools but doesn’t win against habits, it’s stuck in nice-to-have territory.
To win, Clado needs to sustain a lead in one (ideally two) of these dimensions:
Quality: consistently better lists for complex prompts, measured by external benchmarks and customer outcomes.
Cost/time: materially faster list creation and enrichment, with transparent pricing.
Trust: security/compliance posture that makes enterprise adoption possible.
Embedding: become the people-search API other tools build on, creating distribution leverage.
Clado’s competitive advantages:
Agentic evaluation layer: parallel scoring rather than pure filter matching.
Unified profile concept: connect identities across GitHub/Twitter/etc into one searchable object.
Usage-based pricing: pay per successful outcome rather than per seat (especially attractive for API users).
Benchmark-forward marketing: publishes comparative Elo and enrichment benchmarks instead of vague claims.
What’s Shipping (and What’s Next)
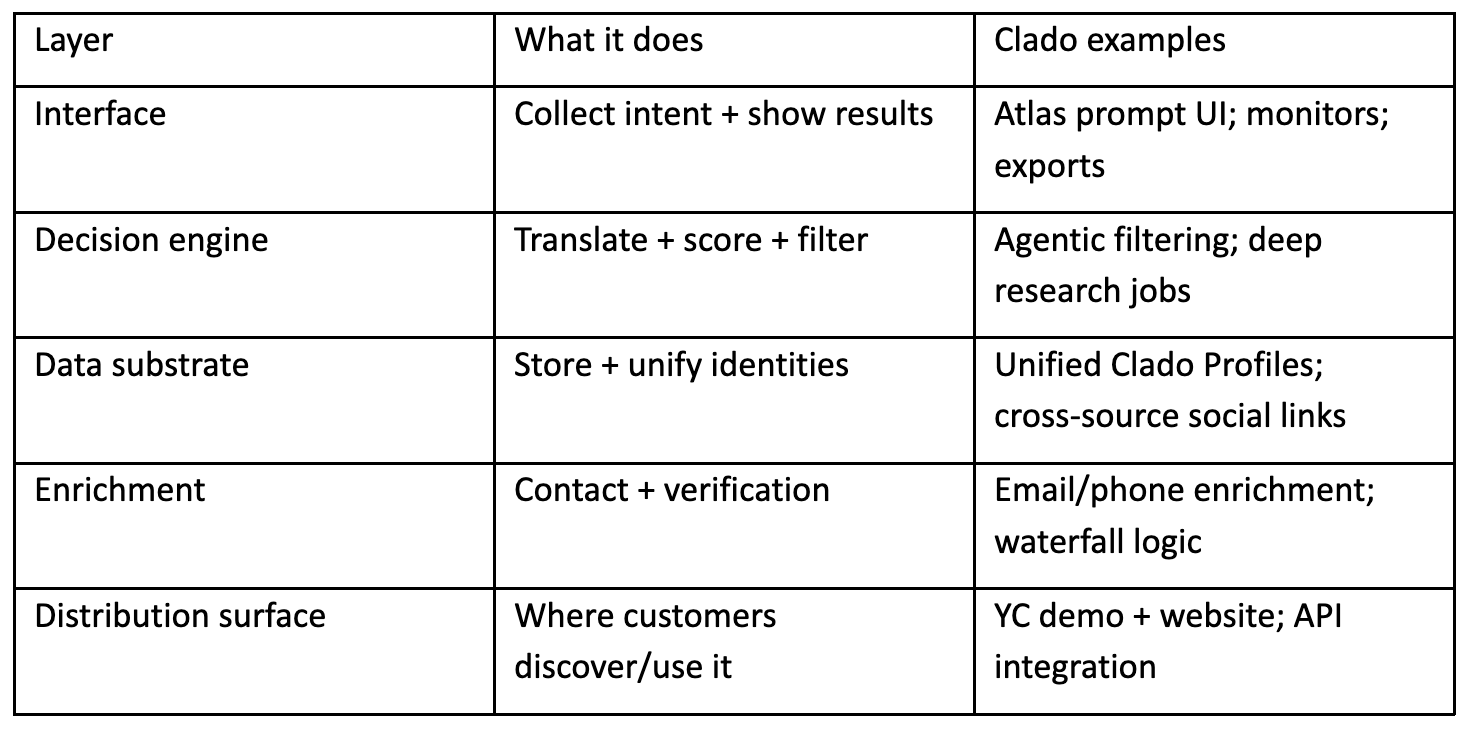
Clado currently presents as a platform with two main entry points:
Atlas (web): prompt-based people search, complex criteria matching, enrichment, exports, and monitors for team workflows.
Search & Enrichment API: programmatic people search, deep research jobs, and enrichment endpoints (emails, phones, profile scraping, post reactions).
Core feature blocks:
Complex criteria matching over 800M+ profiles.
Unified profiles with cross-source identities (LinkedIn, GitHub, Twitter, etc.).
Email/phone enrichment with “pay only if found” semantics on some endpoints.
Asynchronous Deep Research jobs for large-scale searches.
Clado’s public signals suggest a roadmap that’s focused in these areas:
More data sources and richer entity graphs (org charts, academic/publishing metadata, code artifacts).
Better evaluation tooling: more benchmarks, more transparent methodology, and prompt-level quality tracking.
Enterprise features: compliance posture and custom rate limits indicate an enterprise motion.
Workflow integrations: the API plus export-first UI suggests eventual deeper CRM/ATS integrations.
A useful mental model is to map features to layers:
How Clado Gets Paid
Clado’s public disclosures point to a hybrid model: a free/low-friction web product that grows usage, and a paid, usage-based API and enrichment layer that monetizes at the moment value is delivered.
Revenue model:
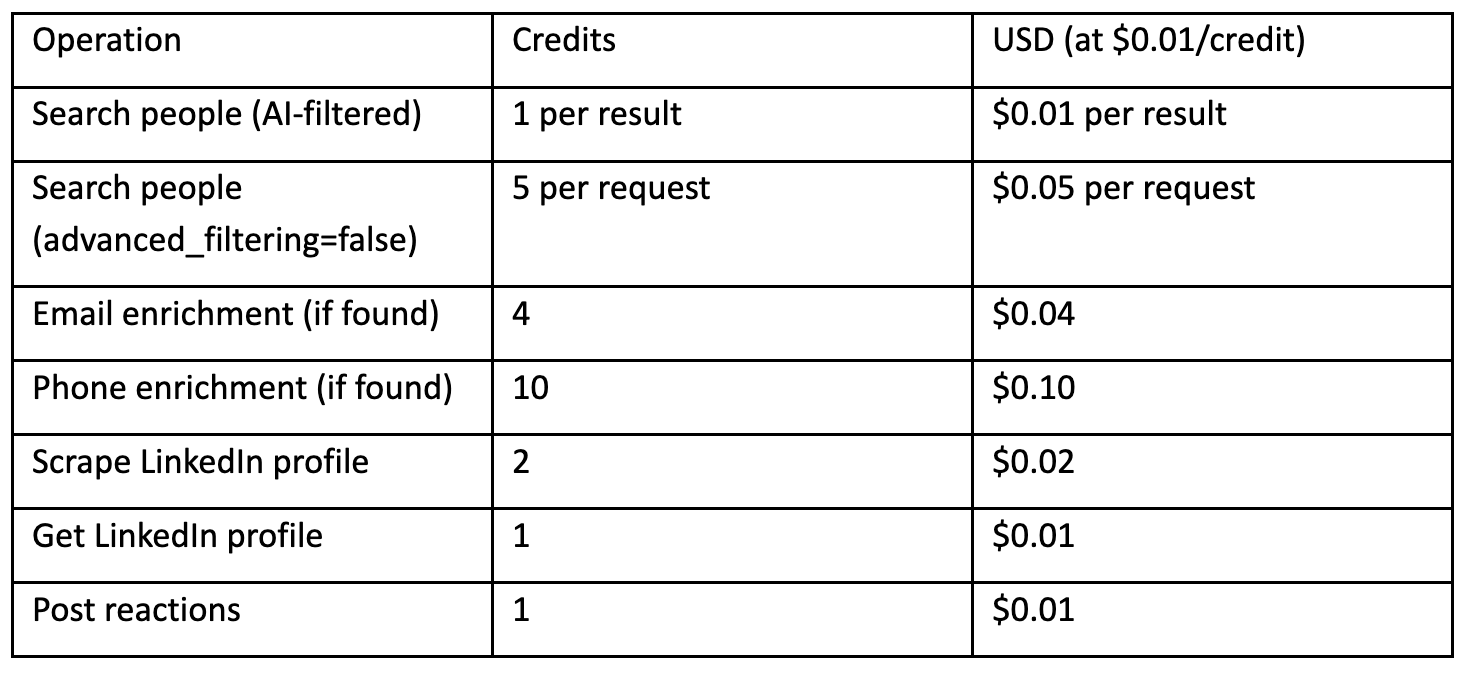
Usage-based API credits: $0.01 per credit; endpoints consume credits per successful outcome.
Higher tiers / enterprise: rate-limit tiers and custom pricing t o support expansion revenue and enterprise contracts.
Potential seat-based upsell: Atlas is team-oriented; enterprise workflows typically bring seat/contract components (but not publicly priced).
Public pricing is clearest on the API side:
Evidence also points to a dual distribution model:
Product-led growth: self-serve sign-up and a simple prompt interface.
Developer adoption: clear docs, transparent pricing, and rate-limit tiers.
Enterprise motion: custom rate limits and custom pricing via sales contact.
Builders, Backgrounds, Incentives
Clado is led by co-founders Tom Zheng and Eric Mao, with a team of seven, with a long-running collaboration and an early pivot from alumni networking to enterprise recruiting/sales workflows.
Additional key roles mentioned in public materials include:
Product / science leadership additions via acquisition of a network graph engine (Jaimy) and team integration.
A bias toward small, technically strong teams.
From an investor/operator lens, the strongest signals here are:
Speed of iteration and willingness to publish technical details and benchmark results.
Engineering pragmatism (e.g., infrastructure migrations for cost/latency).
Distribution leverage via YC and a developer-facing API strategy.
Financials (What We Know, What We Infer)
The team reports average run cost and response times for three configurations (two variants of an open model and one frontier model baseline). This matters because Clado sells results and enrichment at cents per unit; if inference cost is in fractions of a cent, gross margins can be healthy.
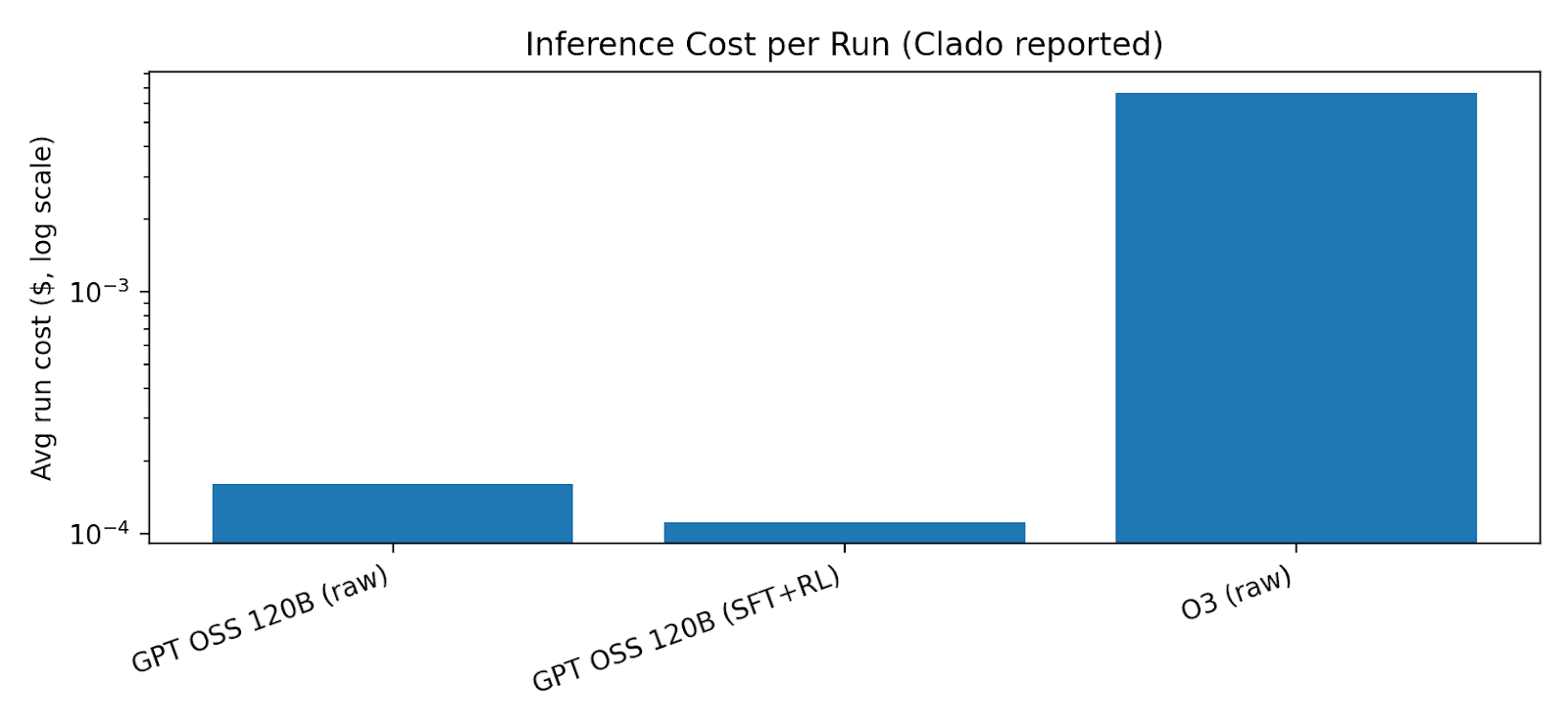
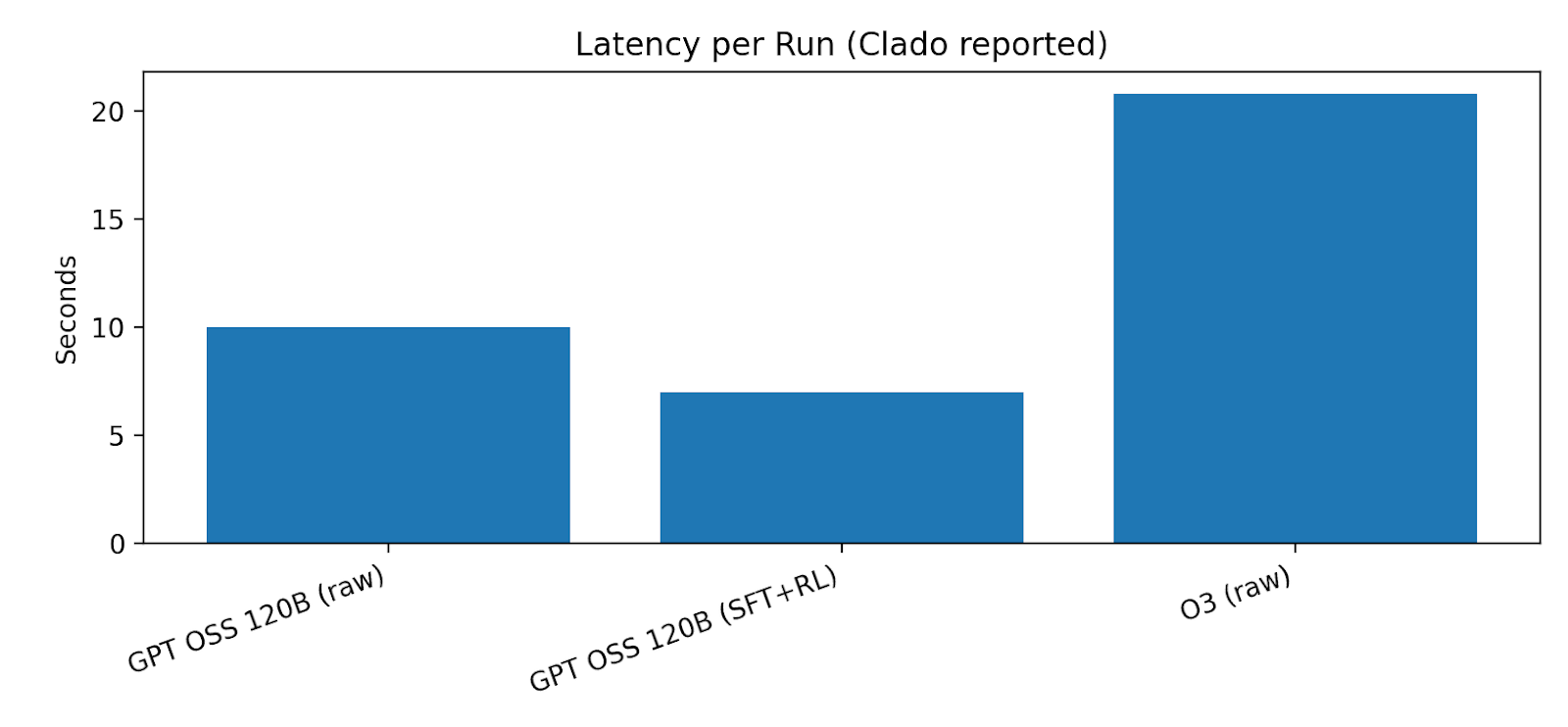
Public reporting suggests the company raised a ~$2M seed raise and the acquisition of Jaimy for stock.. Without statements, the best cash-flow lens is drivers: headcount, cloud spnd (inference + storage), and go-to-market cost. Clado’s own infrastructure details suggest meaningful storage/indexing cost at scale and ongoing inference spend. The strategic goal is obvious: push unit inference cost down faster than price declines, and keep a lean team.
The People Layer of the Internet
Five years out, the optimistic (but plausible) endpoint is that Clado becomes the default programmable ‘people layer’ across the modern work stack: search, identity resolution, enrichment, and relationship graphs exposed via API and embedded into CRMs, ATSs, and analytics tools.
In concrete terms, that future product would look like:
A unified, versioned identity object for each person (sources + confidence + provenance).
Always-on monitors that feed pipelines automatically (hiring, sales, sourcing).
Enterprise governance: audit trails, consent/opt-out flows, bias controls, and compliance tooling as first-class features.
Ecosystem embedding: other tools call Clado the way apps call Stripe (payments) or Twilio (messaging).
A non-exhaustive list of existential risks:
Platform access: if critical upstream sources restrict access or enforce aggressively, coverage and freshness suffer.
Trust/regulation: if enrichment is perceived as invasive or non-compliant, enterprise adoption stalls.
Incumbent bundling: if large platforms integrate equivalent agentic search/enrichment into existing suites, distribution advantage may shrink.
Benchmark fragility: if quality advantages are not durable under adversarial testing, switching costs stay low.