
Baseten: The Inference Utility
Inside the bet that inference becomes the new cloud bill.

Baseten is a production inference infrastructure platform that helps organizations deploy, run, and continuously optimize custom and open-source AI models with high performance and reliability. The company began with a broader productized ML ambition, framing its goal as increasing the value delivered with machine learning by lowerring the barrier to usable, productized ML. By 2024-2026, their center of gravity converged to one thesis, inference, running models in production would become the durable bottleneck for AI products, and therefore the right place to build a differentiated infrastructure business.
Baseten sells the right to stop caring about GPU inference as a bespoke engineering problem. It is an infrastructure service with a chance at a moat if it can make the customer’s unit economics (latency, uptime, cost per token) meaningfully better over time, and make the switching cost painful.
Production AI Breaks in Predictable Ways
Baseten’s core customer is an organization whose product quality and economics are now tightly coupled to inference performance. These teams are judged by:
Latency (time‑to‑first‑token, end‑to‑end response time), because user experience collapses when the model feels slow.
Uptime and graceful failover, because inference outages become product outages.
Throughput and cost‑efficiency (tokens/sec per GPU dollar), because inference is a variable cost that scales with usage.
Iteration speed, because model versions, prompts, and post-training change frequently and must be shipped safely.
Security/compliance, because production inputs/outputs may be sensitive (healthcare, finance, enterprise).
There are three common default solutions for inference at scale, each with predictable failure modes:
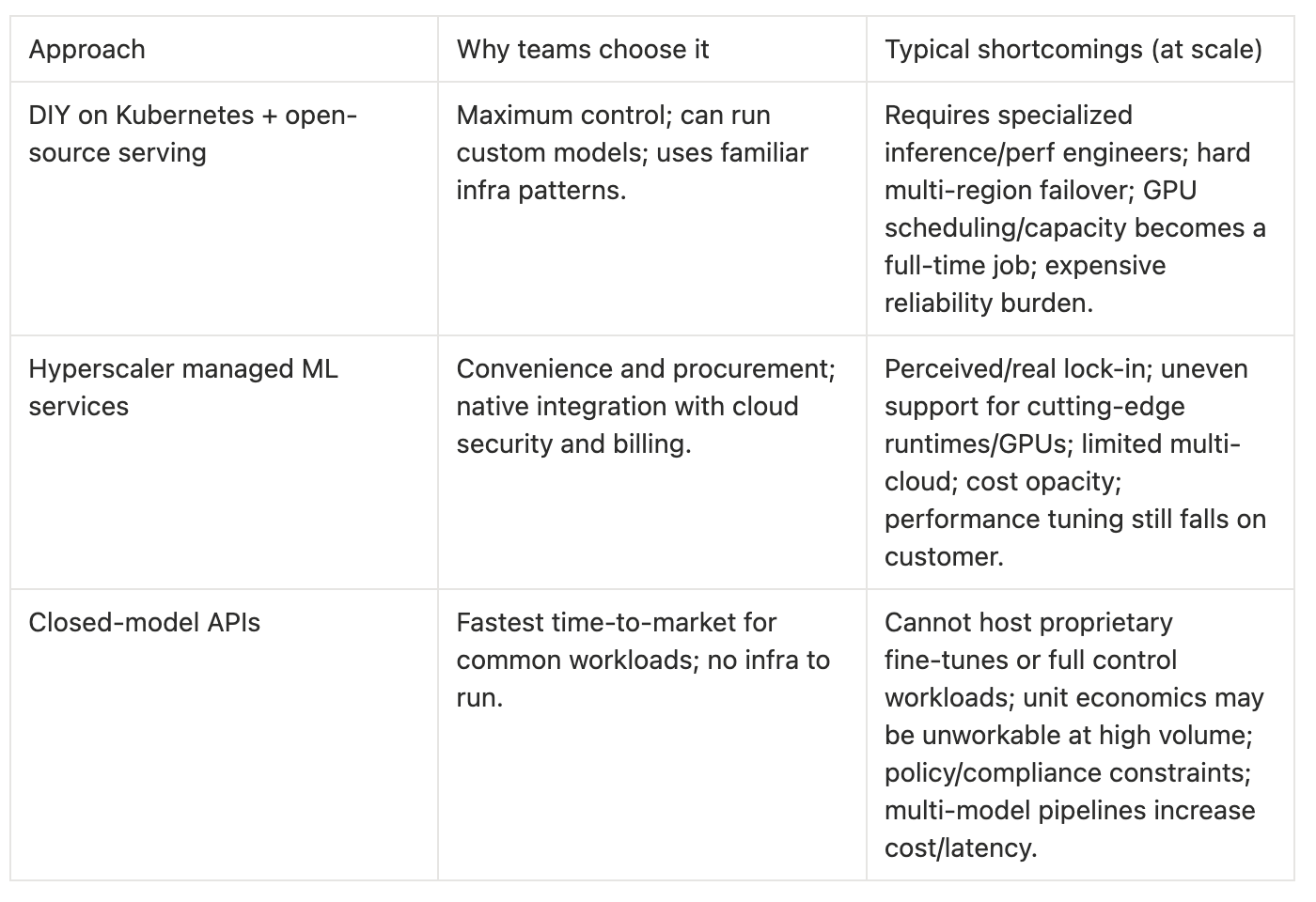
Baseten argues that consistently hitting demanding targets for latency, uptime, and cost requires a holistic view of runtime optimizations plus distributed infrastructure because one-off solutions tend to degrade as models, GPUs, and workloads change.
The Stack: Performance Research, Productized
Baseten’s key insight is that high‑performance inference is a coupled system: model runtime optimizations, infrastructure scheduling/autoscaling, and developer workflows must be designed together. That is why the company markets an Inference Stack: it wants to own the interface between models and production workloads.
Baseten’s value proposition clusters into three compounding advantages:
Performance research as a product surface (custom kernels, decoding techniques, caching).
Inference‑optimized infrastructure (fast cold starts, autoscaling, high availability).
Multi‑cloud capacity management (treat GPU capacity across regions/clouds as one pool; resilience against outages and scarcity).
Baseten claims 99.999% uptime and over 5x year‑over‑year growth while delivering an average 60% better performance than competitors on throughput and latency.
Inference durability comes from churn in the underlying primitives: new models, new GPU generations, new inference techniques, and new workload patterns. Baseten argues that it keeps customers current with day-zero support for new models, continuously updating runtimes and infrastructure so teams do not fall behind.
If Baseten’s internal performance research and infrastructure improvements land faster than customers could replicate, the gap can widen over time.
Baseten’s next phase is a multi‑model future where products rely on specialized models and compound AI workflows. That shifts the platform from single model endpoints toward orchestration, co‑location, and end‑to‑end pipeline optimization.
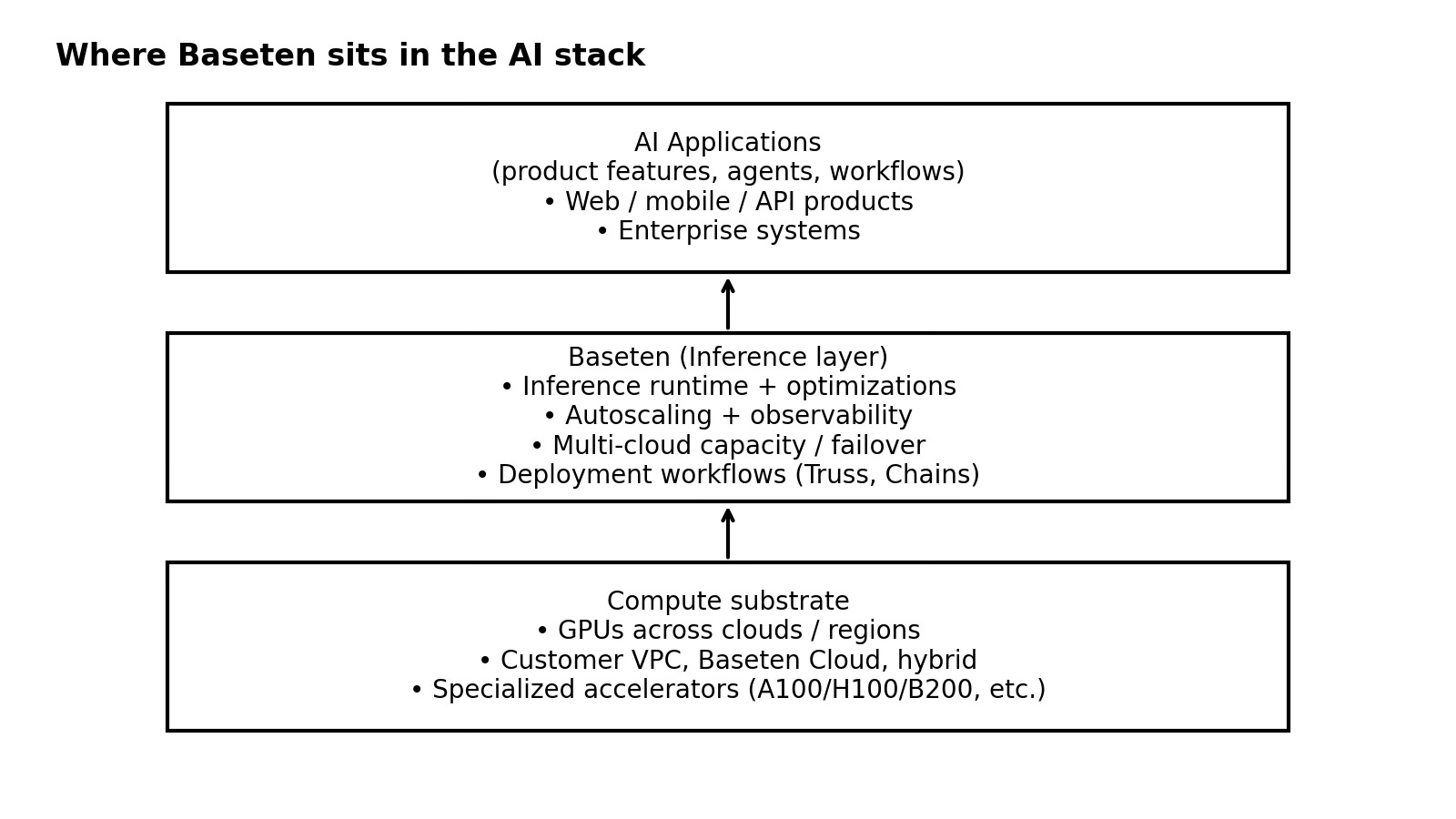
Baseten is downstream of model training and upstream of application logic: it is the system that receives inference requests, runs the model on GPU capacity, and returns outputs under latency/uptime/cost constraints.
Where Baseten shows up in the wild:
Healthcare transcription / clinical documentation: Abridge reportedly generates more than a million clinical notes per week using Baseten.
Medical research search / evidence engines: OpenEvidence reportedly runs billions of custom, fine-tuned LLM calls per week on Baseten.
Enterprise writing assistants / LLM products: Writer’s Palmyra LLMs improved throughput by 60% in a Google Cloud collaboration.
Real-time conversation agents: Scaled Cognition case: TTFT under 120ms and ~40% latency reduction.
Timing: Why Inference Became the Bottleneck
The post‑2022 reality is that inference has become both the dominant scaling constraint and the dominant cost driver for AI products. The 2022 generative AI inflection (ChatGPT) is the moment the market showed up. Inference workloads are larger and structurally different. Multi‑model, more specialized, and increasingly reasoning or reinforcement‑learning‑driven, which increases compute per task.
Historical evolution of the category:

Trends that make Baseten’s solution possible now:

The Prize: Inference Spend Becomes the New Cloud Bill
Baseten operates in the AI inference platform segment: infrastructure and software that runs models in production, across GPUs, regions, and increasingly clouds. This is adjacent to MLOps, but narrower and more performance‑sensitive: the product is the runtime and reliability of production inference.
The customers of Baseten share a pattern:
AI is a core product. Usage scales with end customers.
The company either runs custom / fine‑tuned models, or wants the ability to switch between closed and open models.
They care about strict latency (real-time or interactive) and/or very high throughput (batch workloads, embeddings, indexing).
They are sensitive to platform risk (multi-cloud, compliance, data boundaries).
Baseten has a mix of AI-native products and enterprise AI vendors as customers or partners:
Abridge (healthcare)
OpenEvidence (medical evidence engine)
Writer (enterprise LLM vendor; Palmyra)
Clay (go-to-market automation)
Scaled Cognition (real-time voice agents)
Notion, Cursor, Mercor
TAM (top-down): Baseten’s Series D references an over $100 billion inference market.
SAM (bottom-up, model-based): Baseten’s realistic serviceable market is the subset of inference spend where customers need custom/fine‑tuned/open models, strict performance SLOs, and production-grade reliability/compliance, and are willing to buy an independent platform rather than stay purely inside a hyperscaler-managed service.
Because Baseten is private, the best public SAM estimate is an assumptions‑based model. A reasonable bottom‑up approach is to estimate:
Number of target accounts (AI-native products + high-inference enterprises)
× annual inference platform spend per account (infrastructure + platform margin)
= SAM
For example, if 1,000–2,000 organizations globally reach mission-critical inference scale (a conservative assumption), and each spends $1–5M/year on inference platform services, SAM would be $1B–$10B/year. This range is intentionally broad; it is meant to show the order of magnitude, not a point estimate.
SOM (obtainable share): Baseten has publicly cited high growth rates and large-scale customers; in a five-year view, an obtainable share might be low-single-digit percentage of the serviceable market, depending on hyperscaler competition and Baseten’s ability to scale enterprise go-to-market.
The Battlefield: Hyperscalers, Startups, and “Build It Yourself”
Baseten competes most directly with other managed inference platforms and model-serving infrastructure providers. A non-exhaustive set of direct categories:
Managed inference endpoints (model hosting platforms): Products that host open-source/custom models with autoscaling and billing.
Serverless GPU compute platforms: General-purpose GPU compute with developer-friendly primitives that can be used for inference.
End-to-end MLOps vendors with serving products: Platforms that include inference/serving as one module among many.
GPU cloud providers that bundle serving layers: Capacity-first providers that increasingly add managed serving and observability.
Baseten sees performance and reliability as the decisive battleground (not just who can spin up a container on a GPU).
Indirect competitors and substitutes:
Hyperscaler managed services (AWS, Google Cloud, Azure): Default choice for many enterprises; tight integration with cloud procurement and IAM.
Closed-model APIs (OpenAI, Anthropic, etc.): Substitute when use case fits a general model and the economics/policy constraints are acceptable.
DIY inference teams: Especially for large tech companies or AI labs that treat inference as a core competency.
Baseten’s strategic collaborations with AWS and Google Cloud can be read as both distribution and defense: it sells into hyperscaler ecosystems rather than trying to fight the cloud head-on.
Plan to win:

Competitive advantages:
Integrated stack (runtime + infra + dev workflows): Reduces integration tax and enables system-wide optimization.
Documented performance: Average 60% better throughput/latency vs competitors; 99.999% uptime.
Multi-cloud redundancy: Google Cloud case: automated failover and DWS capacity as a safety valve.
Enterprise posture: Not storing inference inputs/outputs; compliance (SOC 2, HIPAA).
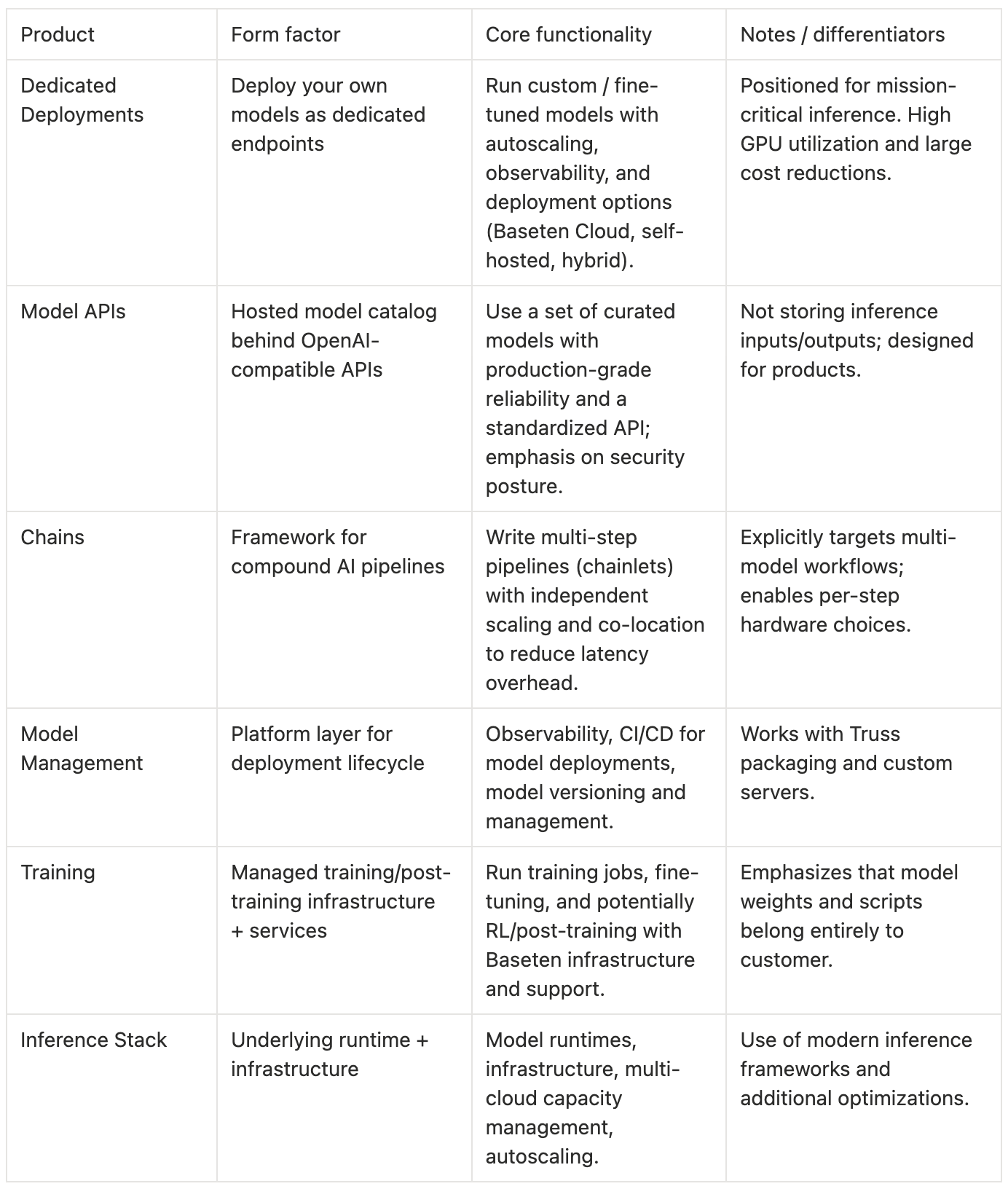
The Inference Stack and Its Surfaces
Baseten’s product taxonomy breaks into how you consume inference and what stack capabilities make that inference good.
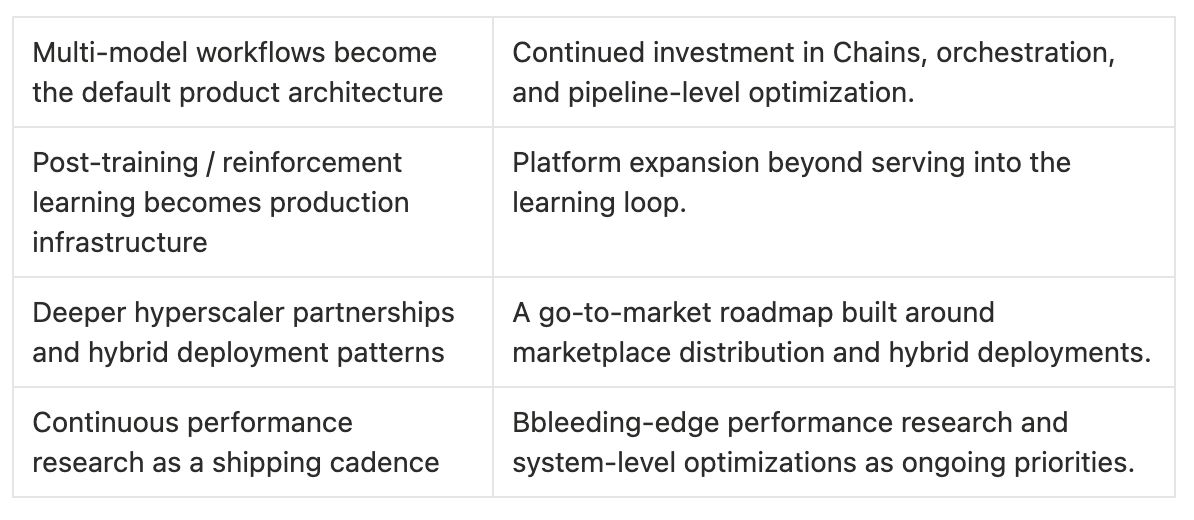
Direction-of-travel bets:
How Baseten Gets Paid: Usage, Enterprise, and Forward-Deployed Leverage
Baseten’s business model thesis: inference is becoming a first-order cost center for AI products, so customers will pay for a platform that improves unit economics and reliability while reducing the need to staff a deep inference/performance team.
Revenue is primarily usage-based:
Compute usage for Dedicated Deployments and Training (GPU time, scaling with traffic).
Per-token or per-request pricing for Model APIs (OpenAI-compatible endpoints).
Enterprise contracts and support/SLAs for large customers.
Baseten publicly lists cloud GPU pricing (usage-based) and model API pricing. Because these prices can change, the safest way to treat them in diligence is as an externally visible signal of product strategy rather than a fixed contract rate.
Several public datapoints indicate the direction of account size:
Series C press release claims basically zero churn, implying sticky deployments once integrated.
Series D press release references customers generating billions of dollars of revenue and large-scale workloads (e.g., million clinical notes/week at Abridge; billions of LLM calls/week at OpenEvidence).
Inference spend tends to scale with product usage; for successful AI-native products, account sizes can become very large.
Baseten appears to blend product-led entry with enterprise distribution:
Product-led entry: Public docs, model APIs, and self-serve pricing create a low-friction starting point.
Enterprise expansion: Compliance, SLAs, hybrid/self-hosted options, and embedded engineers suggest a high-touch motion for large accounts.
Channel partnerships: AWS strategic collaboration; Google Cloud Marketplace onboarding for easier procurement.
The Endgame: Default Runtime for Production AI
Baseten’s clear end-state: be the default production layer for a multi-model future, where companies run a portfolio of specialized models and continuously improve them through post-training.

Failure modes:
Hyperscalers and GPU providers bundle inference performance/reliability features into managed services, compressing platform margins.
Open-source serving stacks become good enough, lowering willingness to pay for managed platforms.
Platform differentiation shifts from infrastructure to proprietary model advantage; inference providers become intermediated.
Cost structure becomes fragile under GPU scarcity cycles; long-term commitments create cash-flow risk.